 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning and Learning with Stochastic Action Sets
Paper and Code
May 07, 2018
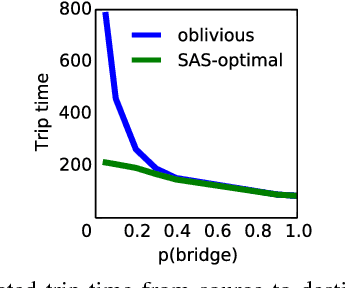
In many practical uses of reinforcement learning (RL) the set of actions available at a given state is a random variable, with realizations governed by an exogenous stochastic process. Somewhat surprisingly, the foundations for such sequential decision processes have been unaddressed. In this work, we formalize and investigate MDPs with stochastic action sets (SAS-MDPs) to provide these foundations. We show that optimal policies and value functions in this model have a structure that admits a compact representation. From an RL perspective, we show that Q-learning with sampled action sets is sound. In model-based settings, we consider two important special cases: when individual actions are available with independent probabilities; and a sampling-based model for unknown distributions. We develop poly-time value and policy iteration methods for both cases; and in the first, we offer a poly-time linear programming solution.