 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchGT: Transformer over Non-trainable Clusters for Learning Graph Representations
Paper and Code
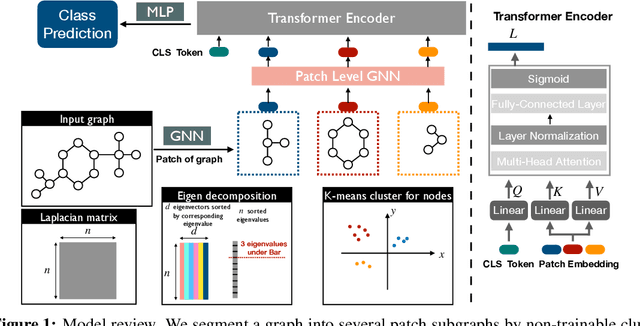


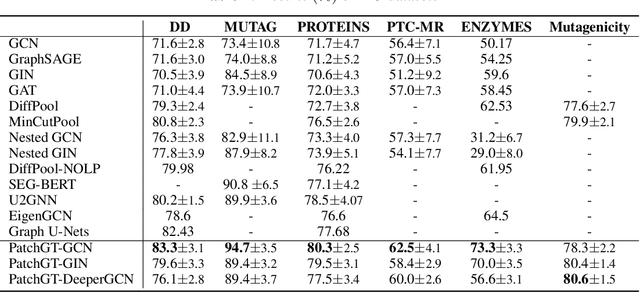
Recently the Transformer structure has shown good performances in graph learning tasks. However, these Transformer models directly work on graph nodes and may have difficulties learning high-level information. Inspired by the vision transformer, which applies to image patches, we propose a new Transformer-based graph neural network: Patch Graph Transformer (PatchGT). Unlike previous transformer-based models for learning graph representations, PatchGT learns from non-trainable graph patches, not from nodes directly. It can help save computation and improve the model performance. The key idea is to segment a graph into patches based on spectral clustering without any trainable parameters, with which the model can first use GNN layers to learn patch-level representations and then use Transformer to obtain graph-level representations. The architecture leverages the spectral information of graphs and combines the strengths of GNNs and Transformers. Further, we show the limitations of previous hierarchical trainable clusters theoretically and empirically. We also prove the proposed non-trainable spectral clustering method is permutation invariant and can help address the information bottlenecks in the graph. PatchGT achieves higher expressiveness than 1-WL-type GNNs, and the empirical study shows that PatchGT achieves competitive performances on benchmark datasets and provides interpretability to its predictions. The implementation of our algorithm is released at our Github repo: https://github.com/tufts-ml/PatchGT.