 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterized Projected Bellman Operator
Paper and Code
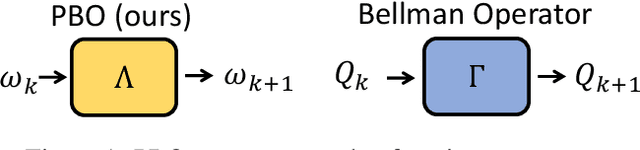



Approximate value iteration~(AVI) is a family of algorithms for reinforcement learning~(RL) that aims to obtain an approximation of the optimal value function. Generally, AVI algorithms implement an iterated procedure where each step consists of (i) an application of the Bellman operator and (ii) a projection step into a considered function space. Notoriously, the Bellman operator leverages transition samples, which strongly determine its behavior, as uninformative samples can result in negligible updates or long detours, whose detrimental effects are further exacerbated by the computationally intensive projection step. To address these issues, we propose a novel alternative approach based on learning an approximate version of the Bellman operator rather than estimating it through samples as in AVI approaches. This way, we are able to (i) generalize across transition samples and (ii) avoid the computationally intensive projection step. For this reason, we call our novel operator projected Bellman operator (PBO). We formulate an optimization problem to learn PBO for generic sequential decision-making problems, and we theoretically analyze its properties in two representative classes of RL problems. Furthermore, we theoretically study our approach under the lens of AVI and devise algorithmic implementations to learn PBO in offline and online settings by leveraging neural network parameterizations. Finally, we empirically showcase the benefits of PBO w.r.t. the regular Bellman operator on several RL problems.