 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Language Priors in Visual Question Answering via Distinguishing Superficially Similar Instances
Paper and Code
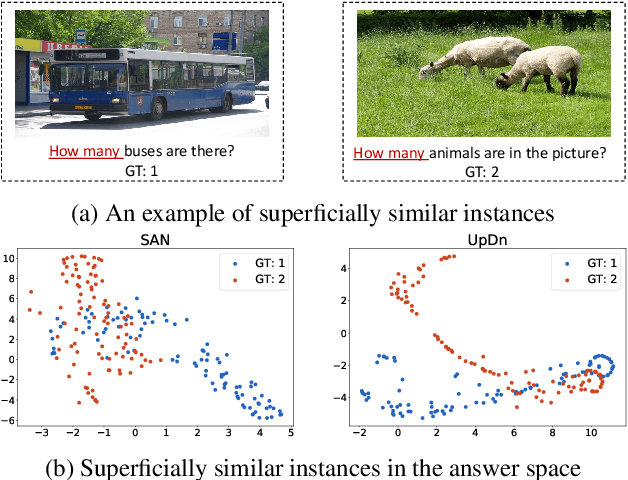
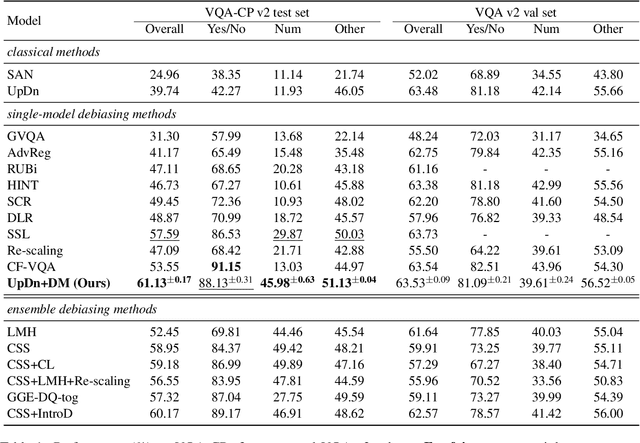
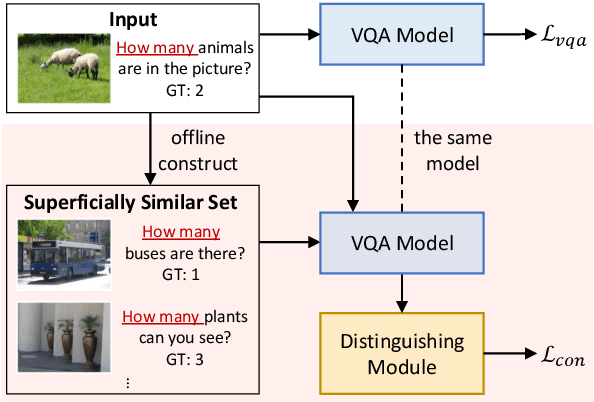
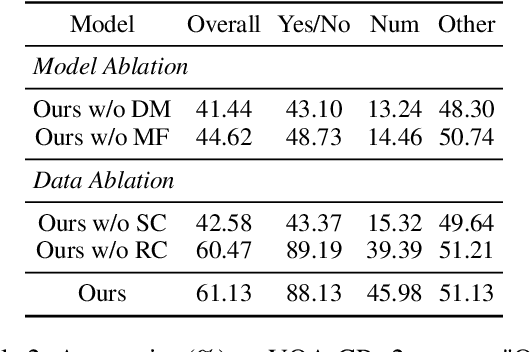
Despite the great progress of Visual Question Answering (VQA), current VQA models heavily rely on the superficial correlation between the question type and its corresponding frequent answers (i.e., language priors) to make predictions, without really understanding the input. In this work, we define the training instances with the same question type but different answers as \textit{superficially similar instances}, and attribute the language priors to the confusion of VQA model on such instances. To solve this problem, we propose a novel training framework that explicitly encourages the VQA model to distinguish between the superficially similar instances. Specifically, for each training instance, we first construct a set that contains its superficially similar counterparts. Then we exploit the proposed distinguishing module to increase the distance between the instance and its counterparts in the answer space. In this way, the VQA model is forced to further focus on the other parts of the input beyond the question type, which helps to overcome the language priors. Experimental results show that our method achieves the state-of-the-art performance on VQA-CP v2. Codes are available at \href{https://github.com/wyk-nku/Distinguishing-VQA.git}{Distinguishing-VQA}.