 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizer Fusion: Efficient Training with Better Locality and Parallelism
Paper and Code

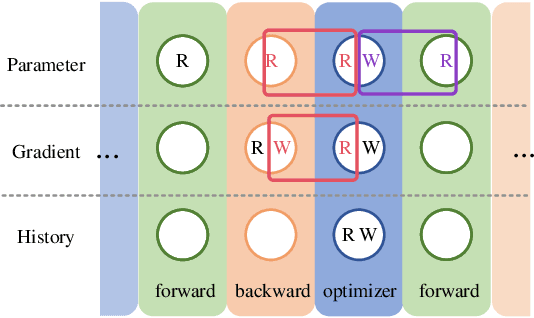

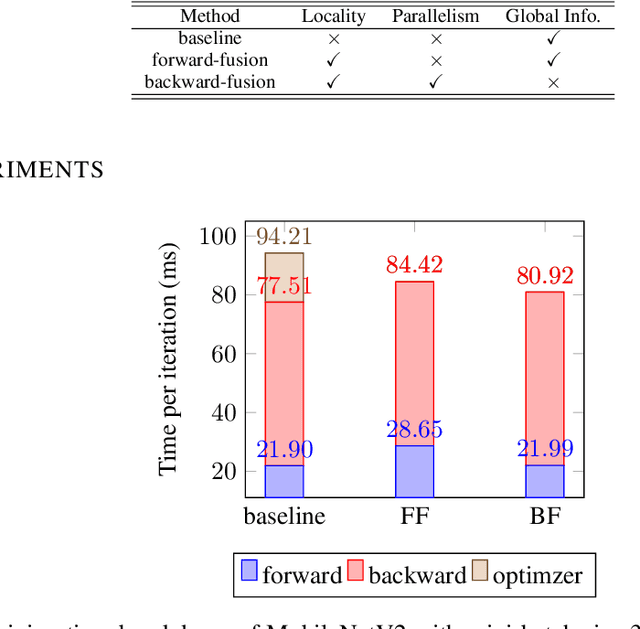
Machine learning frameworks adopt iterative optimizers to train neural networks. Conventional eager execution separates the updating of trainable parameters from forward and backward computations. However, this approach introduces nontrivial training time overhead due to the lack of data locality and computation parallelism. In this work, we propose to fuse the optimizer with forward or backward computation to better leverage locality and parallelism during training. By reordering the forward computation, gradient calculation, and parameter updating, our proposed method improves the efficiency of iterative optimizers. Experimental results demonstrate that we can achieve an up to 20% training time reduction on various configurations. Since our methods do not alter the optimizer algorithm, they can be used as a general "plug-in" technique to the training process.