 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Distillation with Mixed Sample Augmentation
Paper and Code
Jun 24, 2022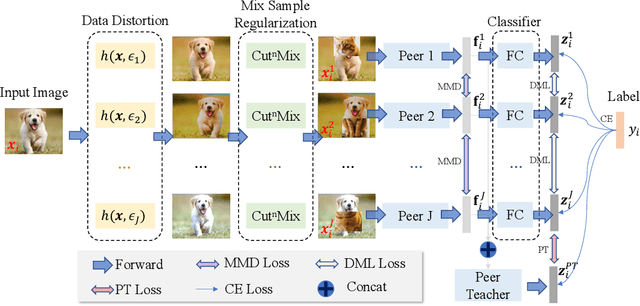
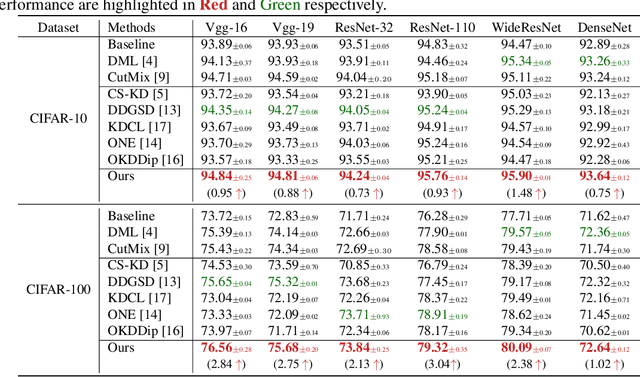
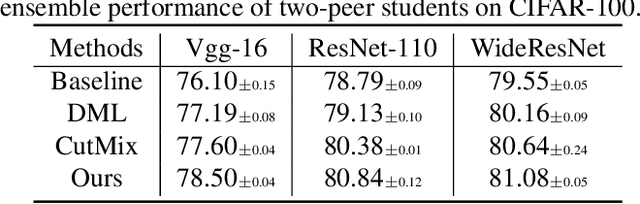
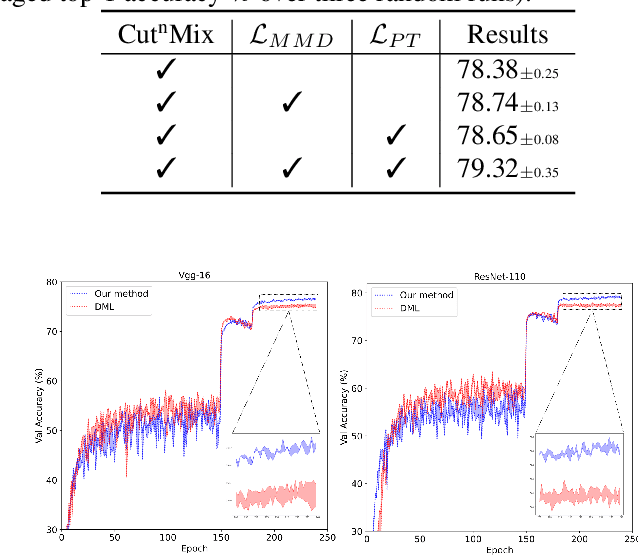
Mixed Sample Regularization (MSR), such as MixUp or CutMix, is a powerful data augmentation strategy to generalize convolutional neural networks. Previous empirical analysis has illustrated an orthogonal performance gain between MSR and the conventional offline Knowledge Distillation (KD). To be more specific, student networks can be enhanced with the involvement of MSR in the training stage of the sequential distillation. Yet, the interplay between MSR and online knowledge distillation, a stronger distillation paradigm, where an ensemble of peer students learn mutually from each other, remains unexplored. To bridge the gap, we make the first attempt at incorporating CutMix into online distillation, where we empirically observe a significant improvement. Encouraged by this fact, we propose an even stronger MSR specifically for online distillation, named as Cut^nMix. Furthermore, a novel online distillation framework is designed upon Cut^nMix, to enhance the distillation with feature level mutual learning and a self-ensemble teacher. Comprehensive evaluations on CIFAR10 and CIFAR100 with six network architectures show that our approach can consistently outperform state-of-the-art distillation methods.