 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot Text Field Labeling using Attention and Belief Propagation for Structure Information Extraction
Paper and Code
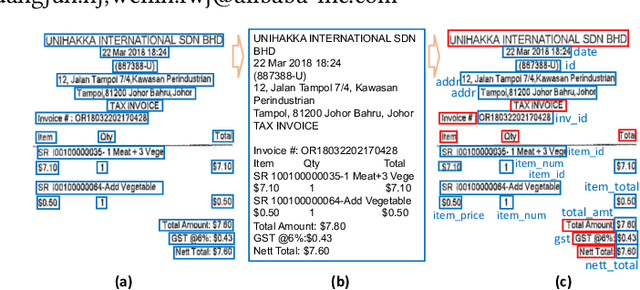
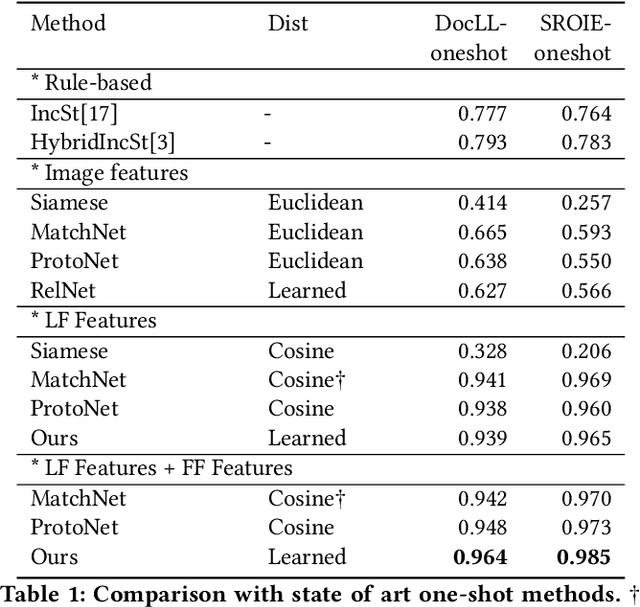
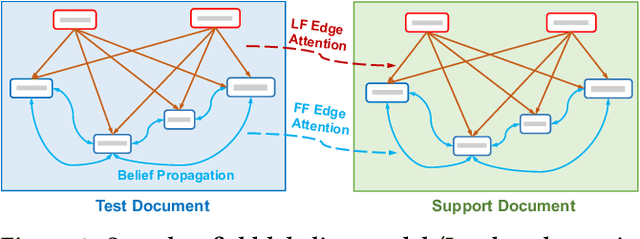
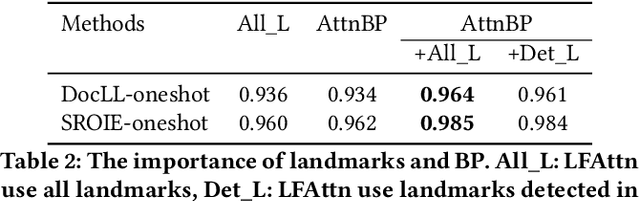
Structured information extraction from document images usually consists of three steps: text detection, text recognition, and text field labeling. While text detection and text recognition have been heavily studied and improved a lot in literature, text field labeling is less explored and still faces many challenges. Existing learning based methods for text labeling task usually require a large amount of labeled examples to train a specific model for each type of document. However, collecting large amounts of document images and labeling them is difficult and sometimes impossible due to privacy issues. Deploying separate models for each type of document also consumes a lot of resources. Facing these challenges, we explore one-shot learning for the text field labeling task. Existing one-shot learning methods for the task are mostly rule-based and have difficulty in labeling fields in crowded regions with few landmarks and fields consisting of multiple separate text regions. To alleviate these problems, we proposed a novel deep end-to-end trainable approach for one-shot text field labeling, which makes use of attention mechanism to transfer the layout information between document images. We further applied conditional random field on the transferred layout information for the refinement of field labeling. We collected and annotated a real-world one-shot field labeling dataset with a large variety of document types and conducted extensive experiments to examine the effectiveness of the proposed model. To stimulate research in this direction, the collected dataset and the one-shot model will be released1.