 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Size Generalization in Graph Neural Networks
Paper and Code
Oct 17, 2020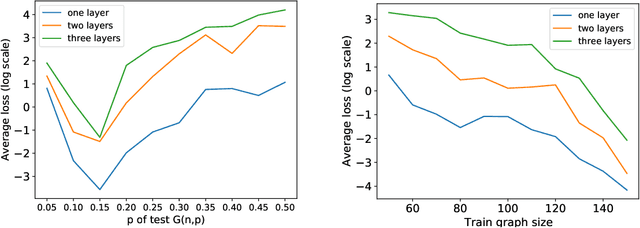


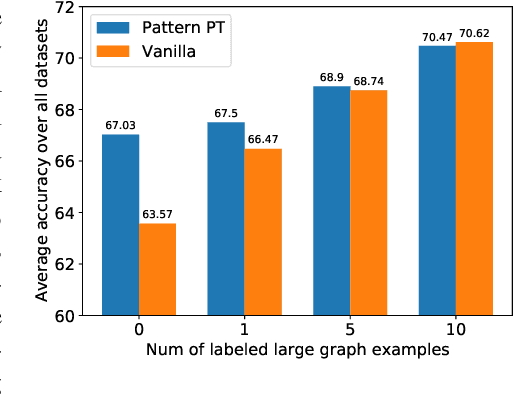
Graph neural networks (GNNs) can process graphs of different sizes but their capacity to generalize across sizes is still not well understood. Size generalization is key to numerous GNN applications, from solving combinatorial optimization problems to learning in molecular biology. In such problems, obtaining labels and training on large graphs can be prohibitively expensive, but training on smaller graphs is possible. This paper puts forward the size-generalization question and characterizes important aspects of that problem theoretically and empirically. We show that even for very simple tasks, GNNs do not naturally generalize to graphs of larger size. Instead, their generalization performance is closely related to the distribution of patterns of connectivity and features and how that distribution changes from small to large graphs. Specifically, we show that in many cases, there are GNNs that can perfectly solve a task on small graphs but generalize poorly to large graphs and that these GNNs are encountered in practice. We then formalize size generalization as a domain-adaption problem and describe two learning setups where size generalization can be improved. First, as a self-supervised learning problem (SSL) over the target domain of large graphs. Second, as a semi-supervised learning problem when few samples are available in the target domain. We demonstrate the efficacy of these solutions on a diverse set of benchmark graph datasets.