 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Addressing Practical Challenges for RNN-Transducer
Paper and Code
May 04, 2021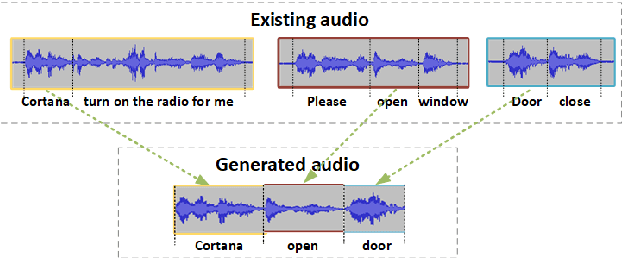

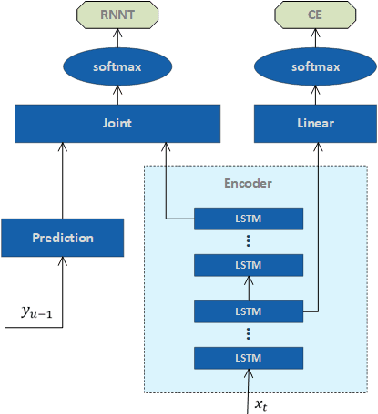

In this paper, several works are proposed to address practical challenges for deploying RNN Transducer (RNN-T) based speech recognition system. These challenges are adapting a well-trained RNN-T model to a new domain without collecting the audio data, obtaining time stamps and confidence scores at word level. The first challenge is solved with a splicing data method which concatenates the speech segments extracted from the source domain data. To get the time stamp, a phone prediction branch is added to the RNN-T model by sharing the encoder for the purpose of force alignment. Finally, we obtain word-level confidence scores by utilizing several types of features calculated during decoding and from confusion network. Evaluated with Microsoft production data, the splicing data adaptation method improves the baseline and adaption with the text to speech method by 58.03% and 15.25% relative word error rate reduction, respectively. The proposed time stamping method can get less than 50ms word timing difference on average while maintaining the recognition accuracy of the RNN-T model. We also obtain high confidence annotation performance with limited computation cost.