 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline versus Online Triplet Mining based on Extreme Distances of Histopathology Patches
Paper and Code
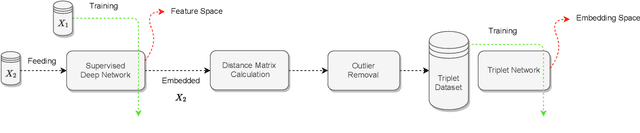
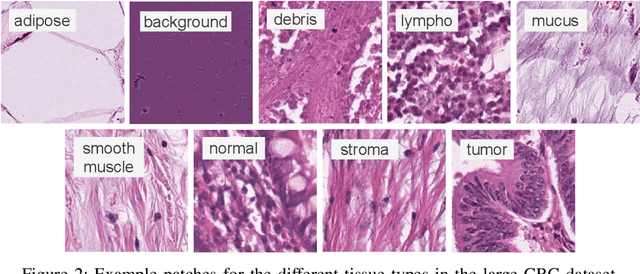
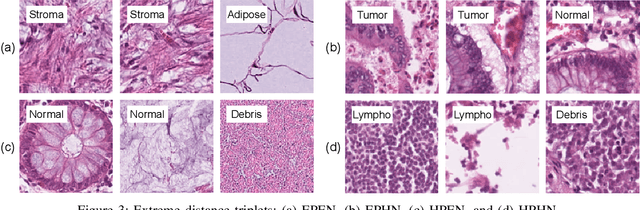
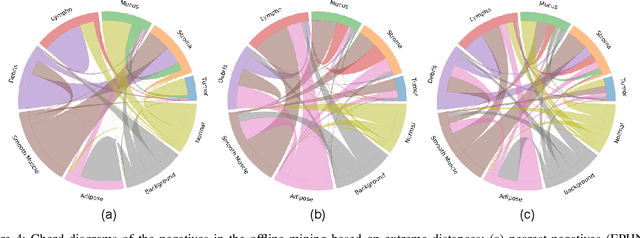
We analyze the effect of offline and online triplet mining for colorectal cancer (CRC) histopathology dataset containing 100,000 patches. We consider the extreme, i.e., farthest and nearest patches with respect to a given anchor, both in online and offline mining. While many works focus solely on how to select the triplets online (batch-wise), we also study the effect of extreme distances and neighbor patches before training in an offline fashion. We analyze the impacts of extreme cases for offline versus online mining, including easy positive, batch semi-hard, and batch hard triplet mining as well as the neighborhood component analysis loss, its proxy version, and distance weighted sampling. We also investigate online approaches based on extreme distance and comprehensively compare the performance of offline and online mining based on the data patterns and explain offline mining as a tractable generalization of the online mining with large mini-batch size. As well, we discuss the relations of different colorectal tissue types in terms of extreme distances. We found that offline mining can generate a better statistical representation of the population by working on the whole dataset.