 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurotoxin: Durable Backdoors in Federated Learning
Paper and Code
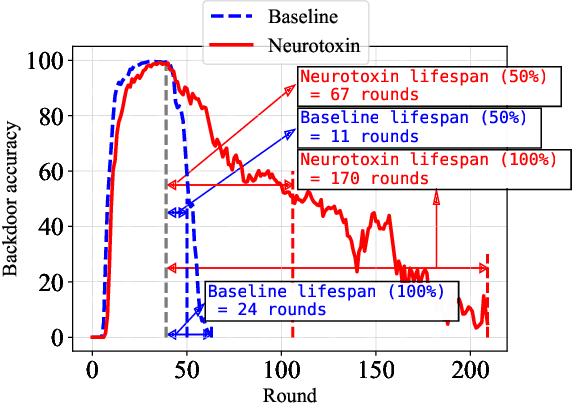

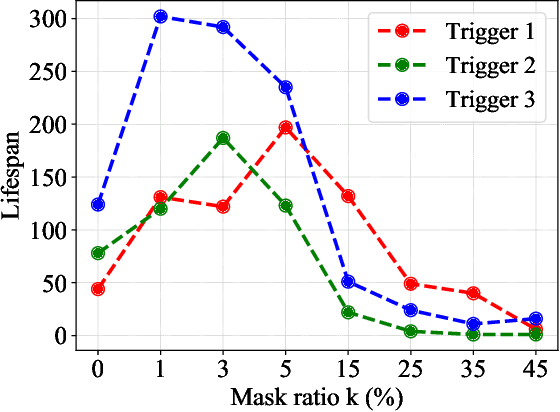
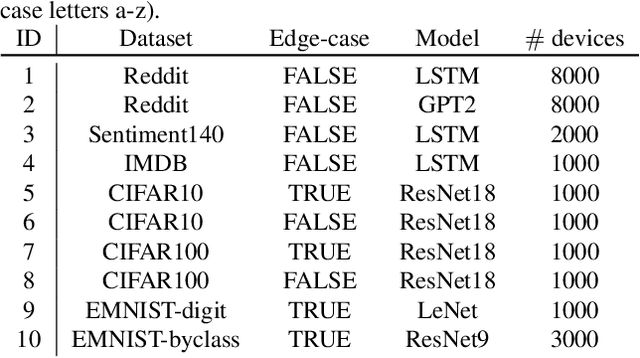
Due to their decentralized nature, federated learning (FL) systems have an inherent vulnerability during their training to adversarial backdoor attacks. In this type of attack, the goal of the attacker is to use poisoned updates to implant so-called backdoors into the learned model such that, at test time, the model's outputs can be fixed to a given target for certain inputs. (As a simple toy example, if a user types "people from New York" into a mobile keyboard app that uses a backdoored next word prediction model, then the model could autocomplete the sentence to "people from New York are rude"). Prior work has shown that backdoors can be inserted into FL models, but these backdoors are often not durable, i.e., they do not remain in the model after the attacker stops uploading poisoned updates. Thus, since training typically continues progressively in production FL systems, an inserted backdoor may not survive until deployment. Here, we propose Neurotoxin, a simple one-line modification to existing backdoor attacks that acts by attacking parameters that are changed less in magnitude during training. We conduct an exhaustive evaluation across ten natural language processing and computer vision tasks, and we find that we can double the durability of state of the art backdoors.