 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighbourhood Representative Sampling for Efficient End-to-end Video Quality Assessment
Paper and Code

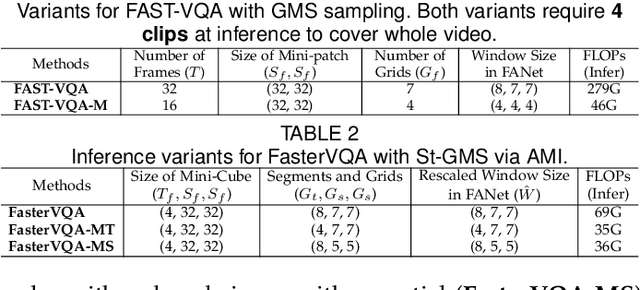
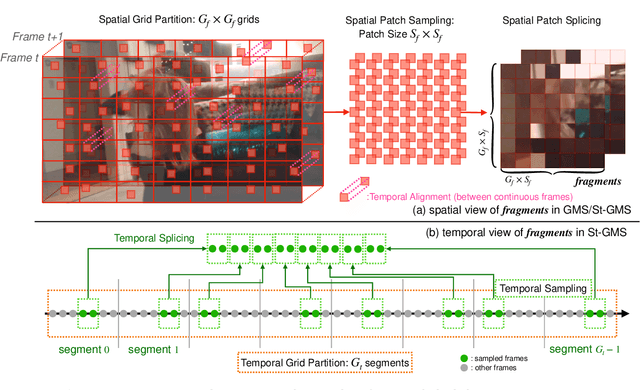
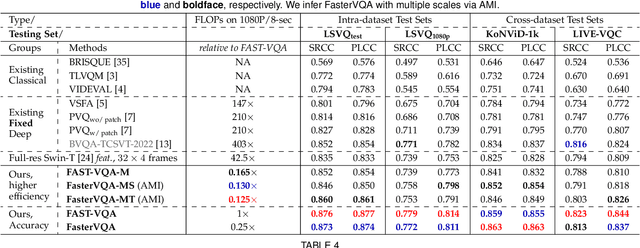
The increased resolution of real-world videos presents a dilemma between efficiency and accuracy for deep Video Quality Assessment (VQA). On the one hand, keeping the original resolution will lead to unacceptable computational costs. On the other hand, existing practices, such as resizing and cropping, will change the quality of original videos due to the loss of details and contents, and are therefore harmful to quality assessment. With the obtained insight from the study of spatial-temporal redundancy in the human visual system and visual coding theory, we observe that quality information around a neighbourhood is typically similar, motivating us to investigate an effective quality-sensitive neighbourhood representatives scheme for VQA. In this work, we propose a unified scheme, spatial-temporal grid mini-cube sampling (St-GMS) to get a novel type of sample, named fragments. Full-resolution videos are first divided into mini-cubes with preset spatial-temporal grids, then the temporal-aligned quality representatives are sampled to compose the fragments that serve as inputs for VQA. In addition, we design the Fragment Attention Network (FANet), a network architecture tailored specifically for fragments. With fragments and FANet, the proposed efficient end-to-end FAST-VQA and FasterVQA achieve significantly better performance than existing approaches on all VQA benchmarks while requiring only 1/1612 FLOPs compared to the current state-of-the-art. Codes, models and demos are available at https://github.com/timothyhtimothy/FAST-VQA-and-FasterVQA.