 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning
Paper and Code
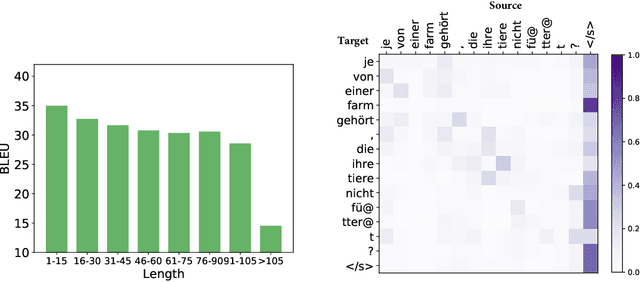



In sequence to sequence learning, the self-attention mechanism proves to be highly effective, and achieves significant improvements in many tasks. However, the self-attention mechanism is not without its own flaws. Although self-attention can model extremely long dependencies, the attention in deep layers tends to overconcentrate on a single token, leading to insufficient use of local information and difficultly in representing long sequences. In this work, we explore parallel multi-scale representation learning on sequence data, striving to capture both long-range and short-range language structures. To this end, we propose the Parallel MUlti-Scale attEntion (MUSE) and MUSE-simple. MUSE-simple contains the basic idea of parallel multi-scale sequence representation learning, and it encodes the sequence in parallel, in terms of different scales with the help from self-attention, and pointwise transformation. MUSE builds on MUSE-simple and explores combining convolution and self-attention for learning sequence representations from more different scales. We focus on machine translation and the proposed approach achieves substantial performance improvements over Transformer, especially on long sequences. More importantly, we find that although conceptually simple, its success in practice requires intricate considerations, and the multi-scale attention must build on unified semantic space. Under common setting, the proposed model achieves substantial performance and outperforms all previous models on three main machine translation tasks. In addition, MUSE has potential for accelerating inference due to its parallelism. Code will be available at https://github.com/lancopku/MUSE