 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMungojerrie: Reinforcement Learning of Linear-Time Objectives
Paper and Code
Jun 18, 2021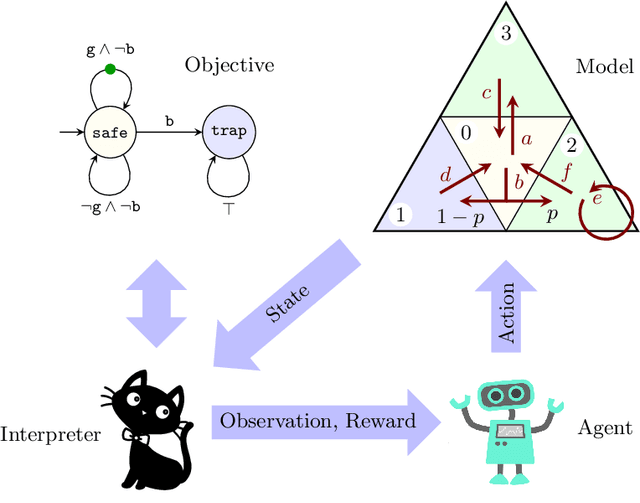


Reinforcement learning synthesizes controllers without prior knowledge of the system. At each timestep, a reward is given. The controllers optimize the discounted sum of these rewards. Applying this class of algorithms requires designing a reward scheme, which is typically done manually. The designer must ensure that their intent is accurately captured. This may not be trivial, and is prone to error. An alternative to this manual programming, akin to programming directly in assembly, is to specify the objective in a formal language and have it "compiled" to a reward scheme. Mungojerrie (https://plv.colorado.edu/mungojerrie/) is a tool for testing reward schemes for $\omega$-regular objectives on finite models. The tool contains reinforcement learning algorithms and a probabilistic model checker. Mungojerrie supports models specified in PRISM and $\omega$-automata specified in HOA.