 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Cauchy Estimator Feature Embedding for Depth and Inertial Sensor-Based Human Action Recognition
Paper and Code
Sep 04, 2016
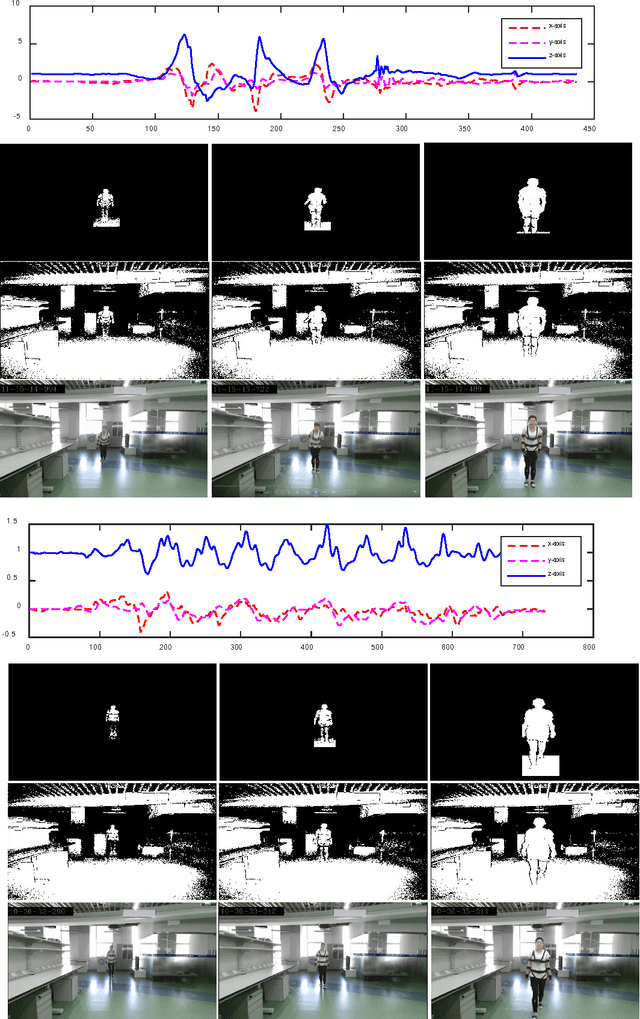
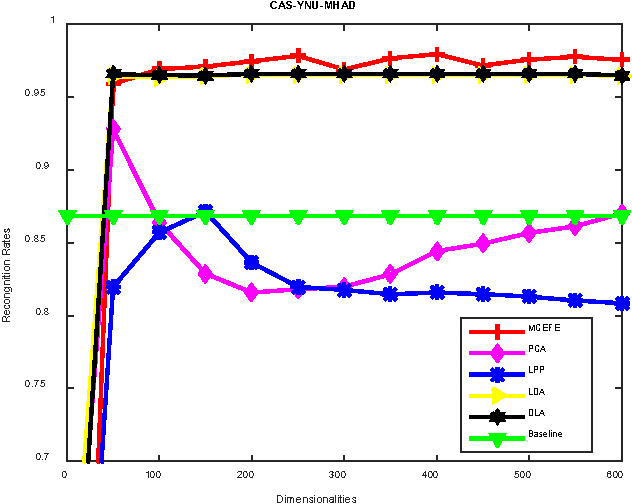
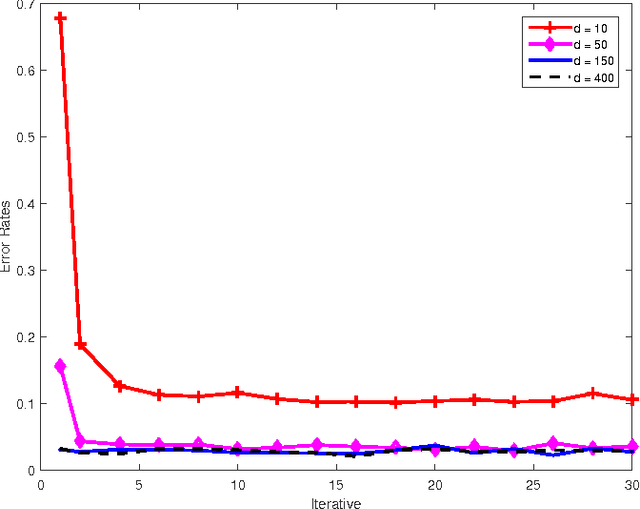
The ever-growing popularity of Kinect and inertial sensors has prompted intensive research efforts on human action recognition. Since human actions can be characterized by multiple feature representations extracted from Kinect and inertial sensors, multiview features must be encoded into a unified space optimal for human action recognition. In this paper, we propose a new unsupervised feature fusion method termed Multiview Cauchy Estimator Feature Embedding (MCEFE) for human action recognition. By minimizing empirical risk, MCEFE integrates the encoded complementary information in multiple views to find the unified data representation and the projection matrices. To enhance robustness to outliers, the Cauchy estimator is imposed on the reconstruction error. Furthermore, ensemble manifold regularization is enforced on the projection matrices to encode the correlations between different views and avoid overfitting. Experiments are conducted on the new Chinese Academy of Sciences - Yunnan University - Multimodal Human Action Database (CAS-YNU-MHAD) to demonstrate the effectiveness and robustness of MCEFE for human action recognition.