 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitrack Music Transformer: Learning Long-Term Dependencies in Music with Diverse Instruments
Paper and Code
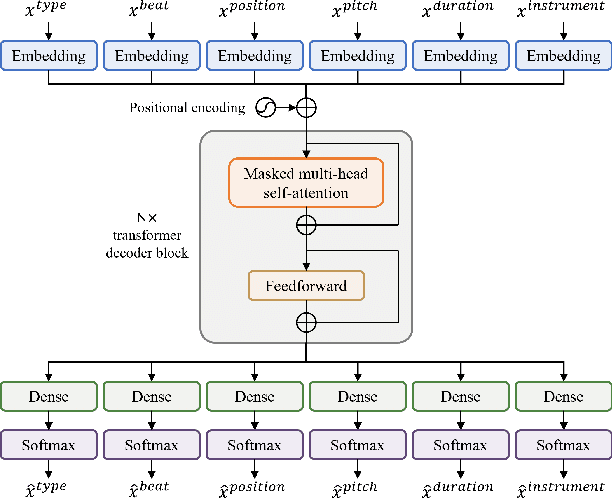
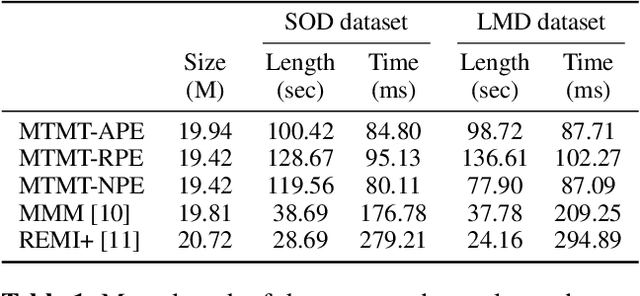


Existing approaches for generating multitrack music with transformer models have been limited to either a small set of instruments or short music segments. This is partly due to the memory requirements of the lengthy input sequences necessitated by existing representations for multitrack music. In this work, we propose a compact representation that allows a diverse set of instruments while keeping a short sequence length. Using our proposed representation, we present the Multitrack Music Transformer (MTMT) for learning long-term dependencies in multitrack music. In a subjective listening test, our proposed model achieves competitive quality on unconditioned generation against two baseline models. We also show that our proposed model can generate samples that are twice as long as those produced by the baseline models, and, further, can do so in half the inference time. Moreover, we propose a new measure for analyzing musical self-attentions and show that the trained model learns to pay less attention to notes that form a dissonant interval with the current note, yet attending more to notes that are 4N beats away from current. Finally, our findings provide a novel foundation for future work exploring longer-form multitrack music generation and improving self-attentions for music. All source code and audio samples can be found at https://salu133445.github.io/mtmt/ .