 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Imitation Learning for Linear Dynamical Systems
Paper and Code
Dec 01, 2022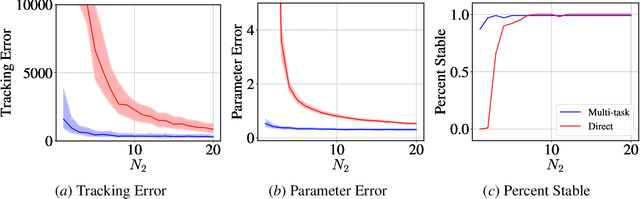
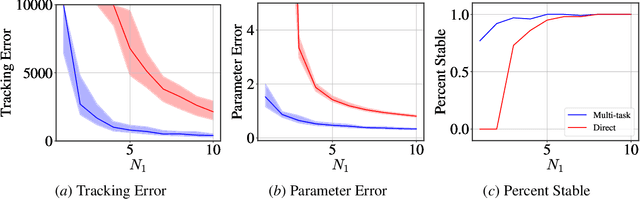
We study representation learning for efficient imitation learning over linear systems. In particular, we consider a setting where learning is split into two phases: (a) a pre-training step where a shared $k$-dimensional representation is learned from $H$ source policies, and (b) a target policy fine-tuning step where the learned representation is used to parameterize the policy class. We find that the imitation gap over trajectories generated by the learned target policy is bounded by $\tilde{O}\left( \frac{k n_x}{HN_{\mathrm{shared}}} + \frac{k n_u}{N_{\mathrm{target}}}\right)$, where $n_x > k$ is the state dimension, $n_u$ is the input dimension, $N_{\mathrm{shared}}$ denotes the total amount of data collected for each policy during representation learning, and $N_{\mathrm{target}}$ is the amount of target task data. This result formalizes the intuition that aggregating data across related tasks to learn a representation can significantly improve the sample efficiency of learning a target task. The trends suggested by this bound are corroborated in simulation.