 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-lingual Common Semantic Space Construction via Cluster-consistent Word Embedding
Paper and Code
Apr 21, 2018
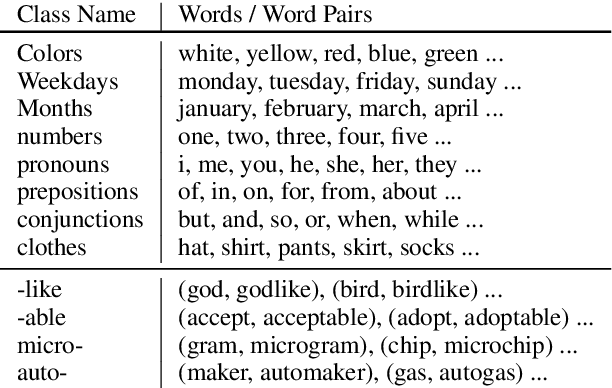


We construct a multilingual common semantic space based on distributional semantics, where words from multiple languages are projected into a shared space to enable knowledge and resource transfer across languages. Beyond word alignment, we introduce multiple cluster-level alignments and enforce the word clusters to be consistently distributed across multiple languages. We exploit three signals for clustering: (1) neighbor words in the monolingual word embedding space; (2) character-level information; and (3) linguistic properties (e.g., apposition, locative suffix) derived from linguistic structure knowledge bases available for thousands of languages. We introduce a new cluster-consistent correlational neural network to construct the common semantic space by aligning words as well as clusters. Intrinsic evaluation on monolingual and multilingual QVEC tasks shows our approach achieves significantly higher correlation with linguistic features than state-of-the-art multi-lingual embedding learning methods do. Using low-resource language name tagging as a case study for extrinsic evaluation, our approach achieves up to 24.5\% absolute F-score gain over the state of the art.