 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-class Hierarchical Question Classification for Multiple Choice Science Exams
Paper and Code



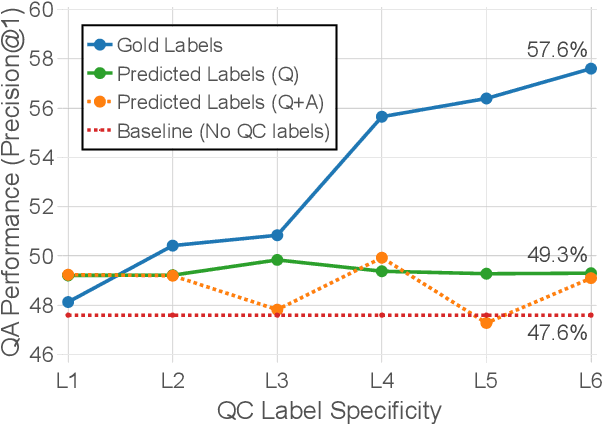
Prior work has demonstrated that question classification (QC), recognizing the problem domain of a question, can help answer it more accurately. However, developing strong QC algorithms has been hindered by the limited size and complexity of annotated data available. To address this, we present the largest challenge dataset for QC, containing 7,787 science exam questions paired with detailed classification labels from a fine-grained hierarchical taxonomy of 406 problem domains. We then show that a BERT-based model trained on this dataset achieves a large (+0.12 MAP) gain compared with previous methods, while also achieving state-of-the-art performance on benchmark open-domain and biomedical QC datasets. Finally, we show that using this model's predictions of question topic significantly improves the accuracy of a question answering system by +1.7% P@1, with substantial future gains possible as QC performance improves.