 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulayCap: Multi-layer Human Performance Capture Using A Monocular Video Camera
Paper and Code
Apr 19, 2020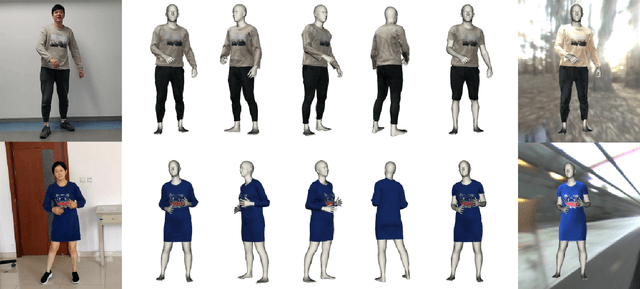
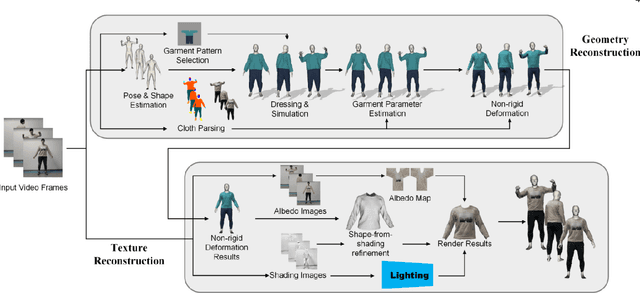
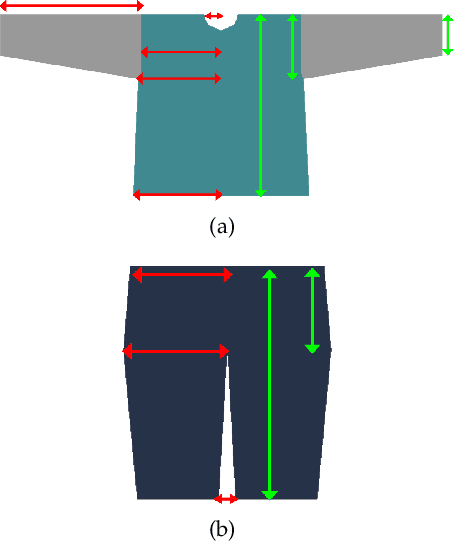
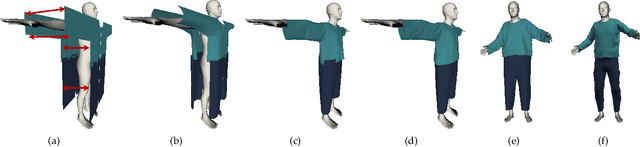
We introduce MulayCap, a novel human performance capture method using a monocular video camera without the need for pre-scanning. The method uses "multi-layer" representations for geometry reconstruction and texture rendering, respectively. For geometry reconstruction, we decompose the clothed human into multiple geometry layers, namely a body mesh layer and a garment piece layer. The key technique behind is a Garment-from-Video (GfV) method for optimizing the garment shape and reconstructing the dynamic cloth to fit the input video sequence, based on a cloth simulation model which is effectively solved with gradient descent. For texture rendering, we decompose each input image frame into a shading layer and an albedo layer, and propose a method for fusing a fixed albedo map and solving for detailed garment geometry using the shading layer. Compared with existing single view human performance capture systems, our "multi-layer" approach bypasses the tedious and time consuming scanning step for obtaining a human specific mesh template. Experimental results demonstrate that MulayCap produces realistic rendering of dynamically changing details that has not been achieved in any previous monocular video camera systems. Benefiting from its fully semantic modeling, MulayCap can be applied to various important editing applications, such as cloth editing, re-targeting, relighting, and AR applications.