 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Depth Estimation for Soft Visuotactile Sensors
Paper and Code
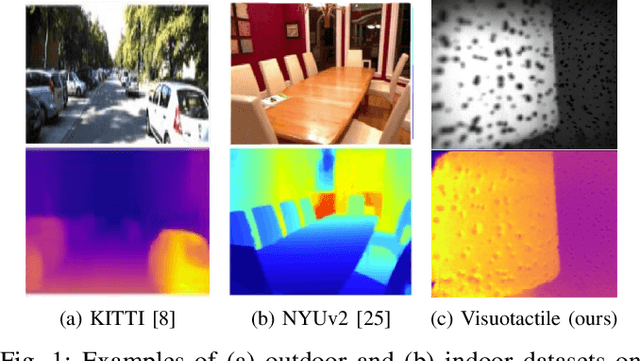
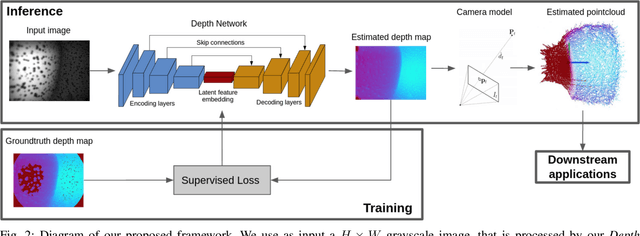


Fluid-filled soft visuotactile sensors such as the Soft-bubbles alleviate key challenges for robust manipulation, as they enable reliable grasps along with the ability to obtain high-resolution sensory feedback on contact geometry and forces. Although they are simple in construction, their utility has been limited due to size constraints introduced by enclosed custom IR/depth imaging sensors to directly measure surface deformations. Towards mitigating this limitation, we investigate the application of state-of-the-art monocular depth estimation to infer dense internal (tactile) depth maps directly from the internal single small IR imaging sensor. Through real-world experiments, we show that deep networks typically used for long-range depth estimation (1-100m) can be effectively trained for precise predictions at a much shorter range (1-100mm) inside a mostly textureless deformable fluid-filled sensor. We propose a simple supervised learning process to train an object-agnostic network requiring less than 10 random poses in contact for less than 10 seconds for a small set of diverse objects (mug, wine glass, box, and fingers in our experiments). We show that our approach is sample-efficient, accurate, and generalizes across different objects and sensor configurations unseen at training time. Finally, we discuss the implications of our approach for the design of soft visuotactile sensors and grippers.