Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Meta-Learning with Shrinkage
Paper and Code
Sep 12, 2019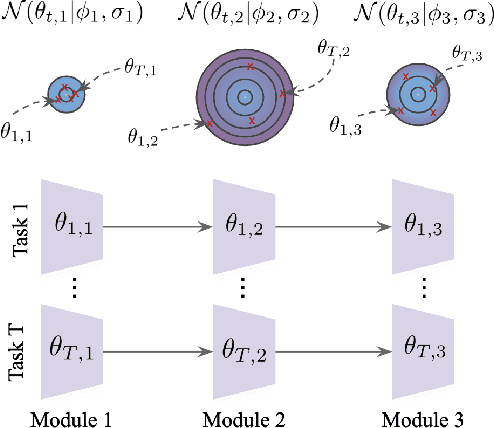
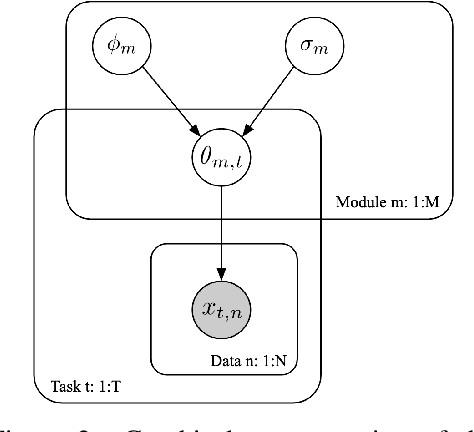
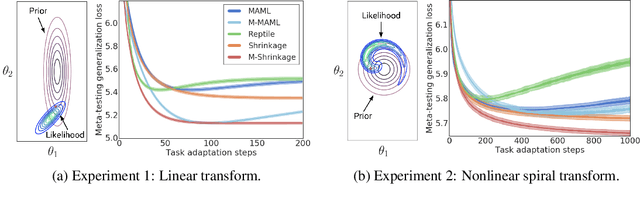
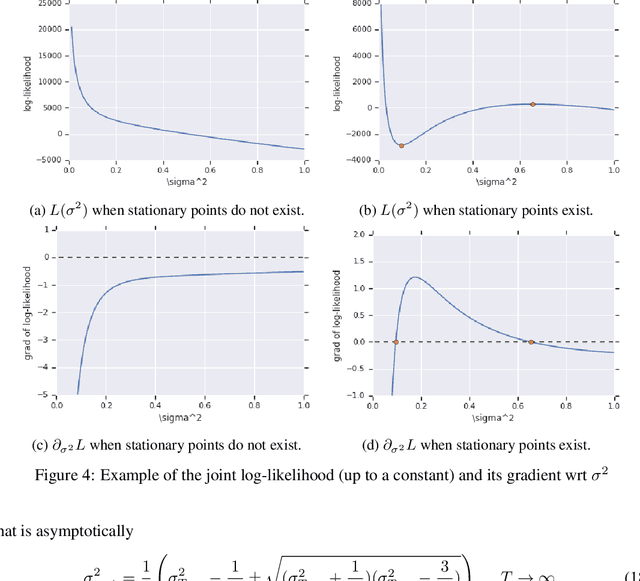
Most gradient-based approaches to meta-learning do not explicitly account for the fact that different parts of the underlying model adapt by different amounts when applied to a new task. For example, the input layers of an image classification convnet typically adapt very little, while the output layers can change significantly. This can cause parts of the model to begin to overfit while others underfit. To address this, we introduce a hierarchical Bayesian model with per-module shrinkage parameters, which we propose to learn by maximizing an approximation of the predictive likelihood using implicit differentiation. Our algorithm subsumes Reptile and outperforms variants of MAML on two synthetic few-shot meta-learning problems.
* 14 pages (4 main, 8 supplement), under review
View paper on