 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Paragraph-Level Vision-Language Semantic Alignment for Multi-Modal Summarization
Paper and Code
Aug 24, 2022
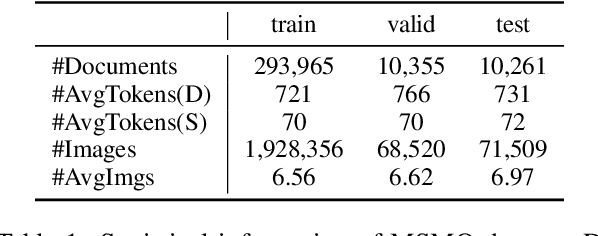
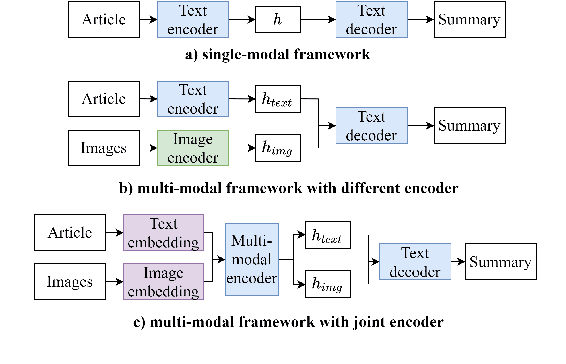
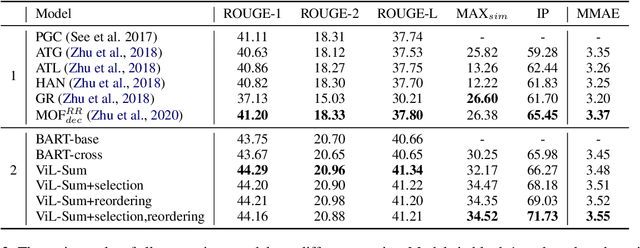
Most current multi-modal summarization methods follow a cascaded manner, where an off-the-shelf object detector is first used to extract visual features, then these features are fused with language representations to generate the summary with an encoder-decoder model. The cascaded way cannot capture the semantic alignments between images and paragraphs, which are crucial to a precise summary. In this paper, we propose ViL-Sum to jointly model paragraph-level \textbf{Vi}sion-\textbf{L}anguage Semantic Alignment and Multi-Modal \textbf{Sum}marization. The core of ViL-Sum is a joint multi-modal encoder with two well-designed tasks, image reordering and image selection. The joint multi-modal encoder captures the interactions between modalities, where the reordering task guides the model to learn paragraph-level semantic alignment and the selection task guides the model to selected summary-related images in the final summary. Experimental results show that our proposed ViL-Sum significantly outperforms current state-of-the-art methods. In further analysis, we find that two well-designed tasks and joint multi-modal encoder can effectively guide the model to learn reasonable paragraphs-images and summary-images relations.