 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPruning: A Multilevel Structured Pruning Framework for Transformer-based Models
Paper and Code
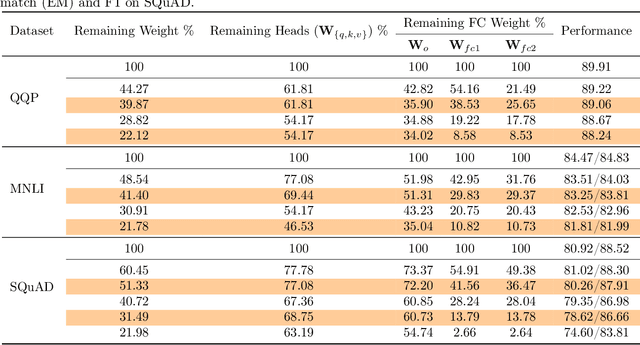
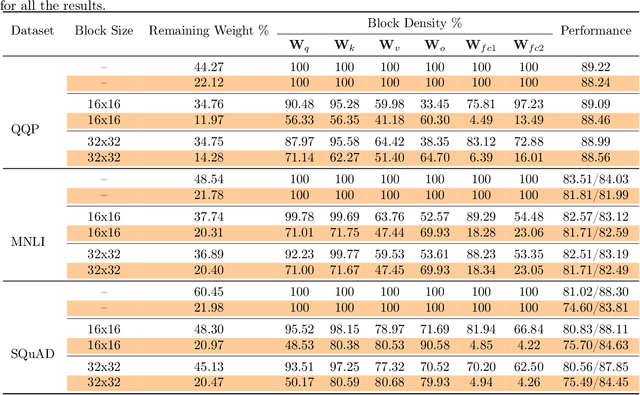
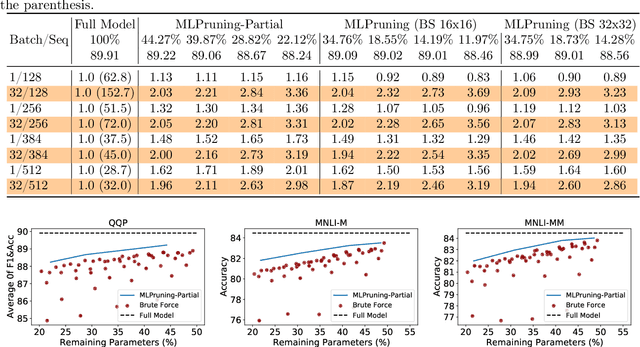
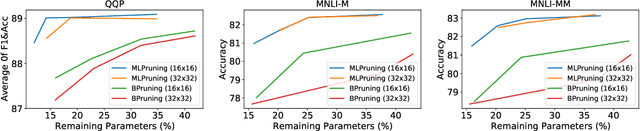
Pruning is an effective method to reduce the memory footprint and computational cost associated with large natural language processing models. However, current approaches either only explore head pruning, which has a limited pruning ratio, or only focus on unstructured pruning, which has negligible effects on the real inference time and/or power consumption. To address these challenges, we develop a novel MultiLevel structured Pruning (MLPruning) framework, which uses three different levels of structured pruning: head pruning, row pruning, and block-wise sparse pruning. We propose using a learnable Top-k threshold, which employs an adaptive regularization to adjust the regularization magnitude adaptively, to select appropriate pruning ratios for different weight matrices. We also propose a two-step pipeline to combine block-wise pruning with head/row pruning to achieve high structured pruning ratios with minimum accuracy degradation. Our empirical results show that for \bertbase, with \textapprox20\% of remaining weights, \OURS can achieve an accuracy that is comparable to the full model on QQP/MNLI/\squad, with up to \textapprox3.69x speedup. Our framework has been open sourced~\cite{codebase}.