 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLCVNet: Multi-Level Context VoteNet for 3D Object Detection
Paper and Code



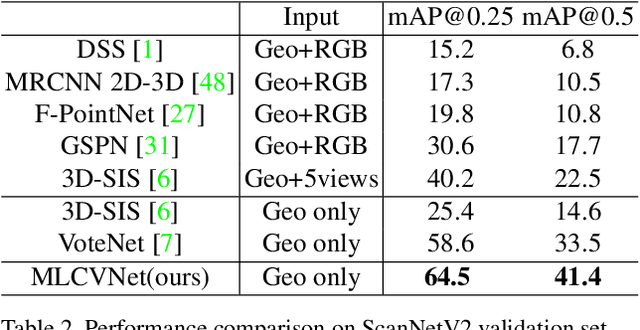
In this paper, we address the 3D object detection task by capturing multi-level contextual information with the self-attention mechanism and multi-scale feature fusion. Most existing 3D object detection methods recognize objects individually, without giving any consideration on contextual information between these objects. Comparatively, we propose Multi-Level Context VoteNet (MLCVNet) to recognize 3D objects correlatively, building on the state-of-the-art VoteNet. We introduce three context modules into the voting and classifying stages of VoteNet to encode contextual information at different levels. Specifically, a Patch-to-Patch Context (PPC) module is employed to capture contextual information between the point patches, before voting for their corresponding object centroid points. Subsequently, an Object-to-Object Context (OOC) module is incorporated before the proposal and classification stage, to capture the contextual information between object candidates. Finally, a Global Scene Context (GSC) module is designed to learn the global scene context. We demonstrate these by capturing contextual information at patch, object and scene levels. Our method is an effective way to promote detection accuracy, achieving new state-of-the-art detection performance on challenging 3D object detection datasets, i.e., SUN RGBD and ScanNet. We also release our code at https://github.com/NUAAXQ/MLCVNet.