 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisalignment Resilient Diffractive Optical Networks
Paper and Code
May 23, 2020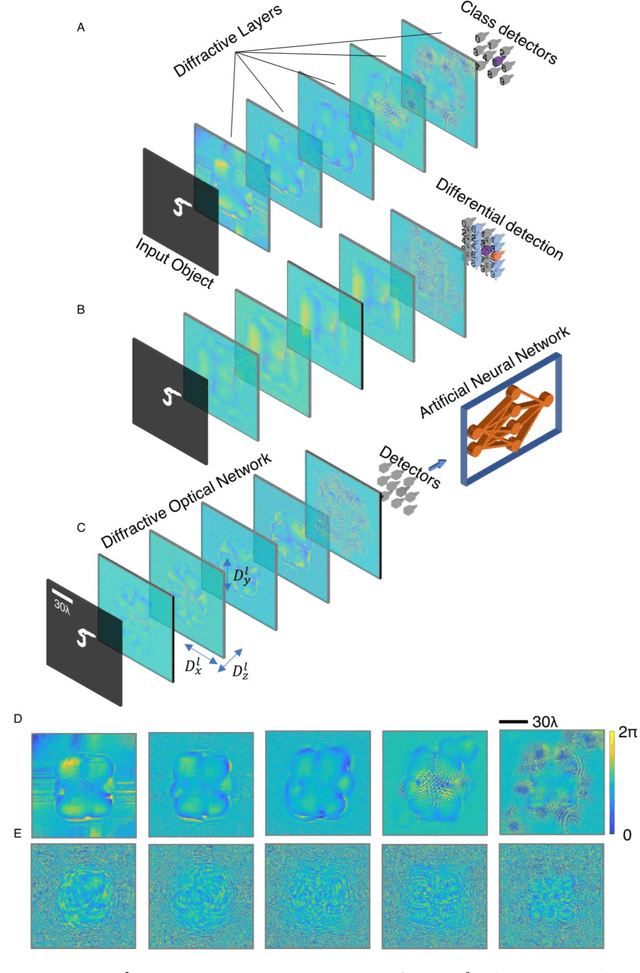
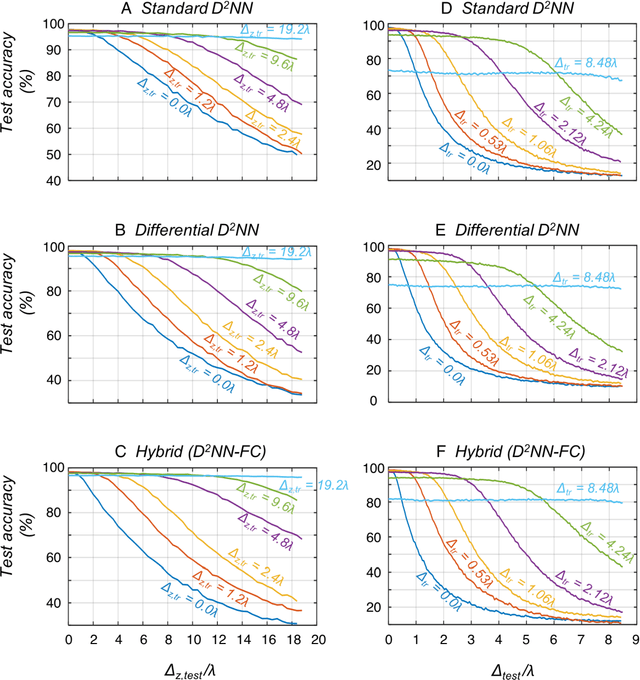
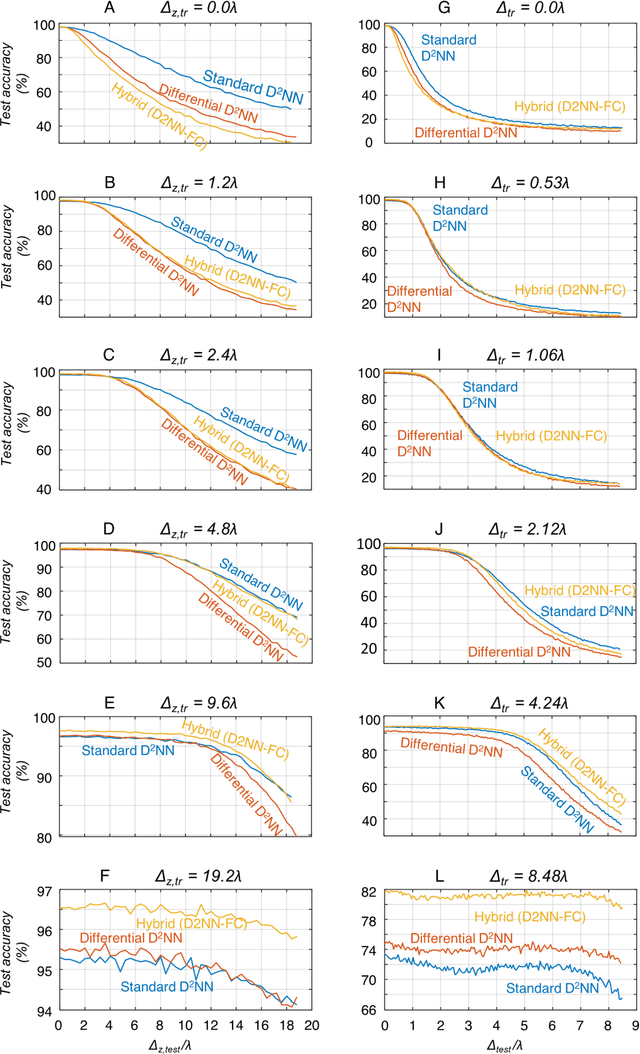
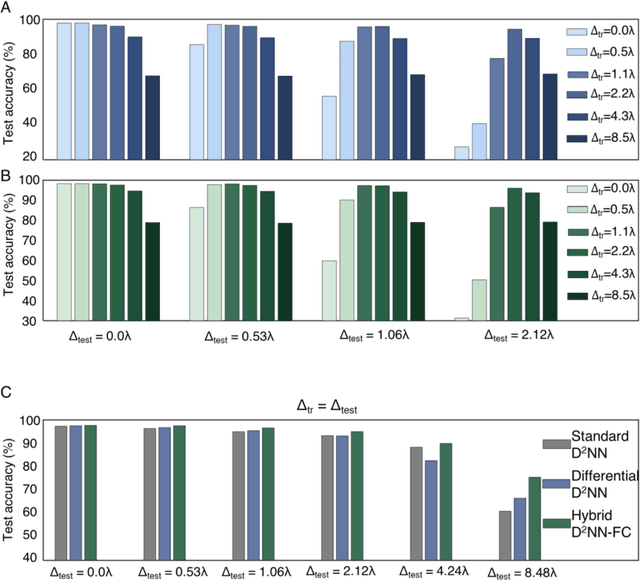
As an optical machine learning framework, Diffractive Deep Neural Networks (D2NN) take advantage of data-driven training methods used in deep learning to devise light-matter interaction in 3D for performing a desired statistical inference task. Multi-layer optical object recognition platforms designed with this diffractive framework have been shown to generalize to unseen image data achieving e.g., >98% blind inference accuracy for hand-written digit classification. The multi-layer structure of diffractive networks offers significant advantages in terms of their diffraction efficiency, inference capability and optical signal contrast. However, the use of multiple diffractive layers also brings practical challenges for the fabrication and alignment of these diffractive systems for accurate optical inference. Here, we introduce and experimentally demonstrate a new training scheme that significantly increases the robustness of diffractive networks against 3D misalignments and fabrication tolerances in the physical implementation of a trained diffractive network. By modeling the undesired layer-to-layer misalignments in 3D as continuous random variables in the optical forward model, diffractive networks are trained to maintain their inference accuracy over a large range of misalignments; we term this diffractive network design as vaccinated D2NN (v-D2NN). We further extend this vaccination strategy to the training of diffractive networks that use differential detectors at the output plane as well as to jointly-trained hybrid (optical-electronic) networks to reveal that all of these diffractive designs improve their resilience to misalignments by taking into account possible 3D fabrication variations and displacements during their training phase.