 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHMS: Multimodal Hierarchical Multimedia Summarization
Paper and Code
Apr 07, 2022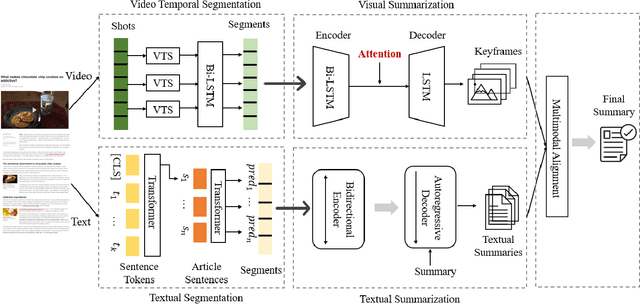
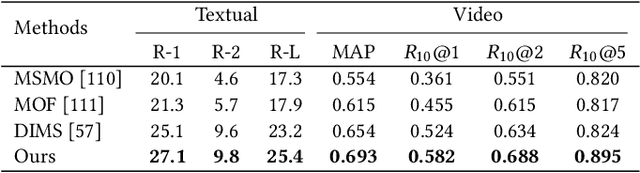
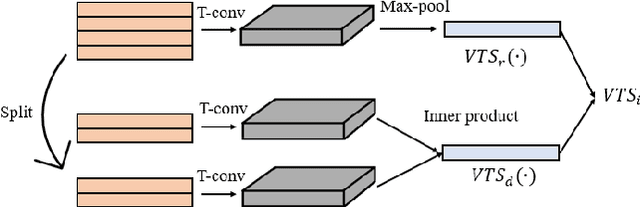

Multimedia summarization with multimodal output can play an essential role in real-world applications, i.e., automatically generating cover images and titles for news articles or providing introductions to online videos. In this work, we propose a multimodal hierarchical multimedia summarization (MHMS) framework by interacting visual and language domains to generate both video and textual summaries. Our MHMS method contains video and textual segmentation and summarization module, respectively. It formulates a cross-domain alignment objective with optimal transport distance which leverages cross-domain interaction to generate the representative keyframe and textual summary. We evaluated MHMS on three recent multimodal datasets and demonstrated the effectiveness of our method in producing high-quality multimodal summaries.