 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching Images and Text with Multi-modal Tensor Fusion and Re-ranking
Paper and Code
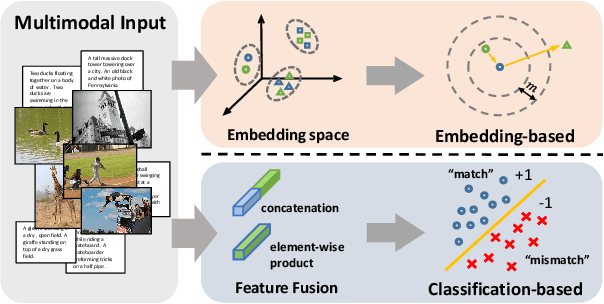
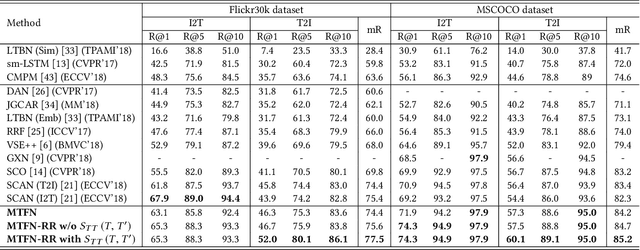
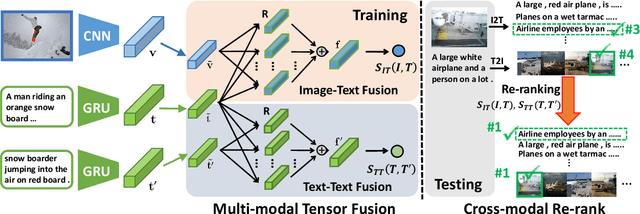
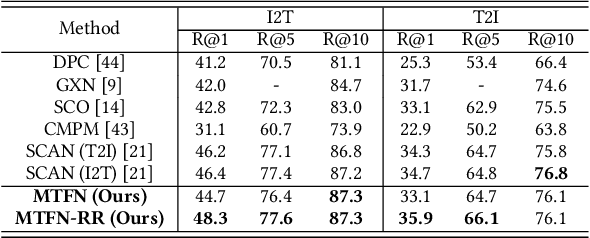
A major challenge in matching images and text is that they have intrinsically different data distributions and feature representations. Most existing approaches are based either on embedding or classification, the first one mapping image and text instances into a common embedding space for distance measuring, and the second one regarding image-text matching as a binary classification problem. Neither of these approaches can, however, balance the matching accuracy and model complexity well. We propose a novel framework that achieves remarkable matching performance with acceptable model complexity. Specifically, in the training stage, we propose a novel Multi-modal Tensor Fusion Network (MTFN) to explicitly learn an accurate image-text similarity function with rank-based tensor fusion rather than seeking a common embedding space for each image-text instance. Then, during testing, we deploy a generic Cross-modal Re-ranking (RR) scheme for refinement without requiring additional training procedure. Extensive experiments on two datasets demonstrate that our MTFN-RR consistently achieves the state-of-the-art matching performance with much less time complexity. The implementation code is available at https://github.com/Wangt-CN/MTFN-RR-PyTorch-Code.