 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping the Ictal-Interictal-Injury Continuum Using Interpretable Machine Learning
Paper and Code
Nov 14, 2022


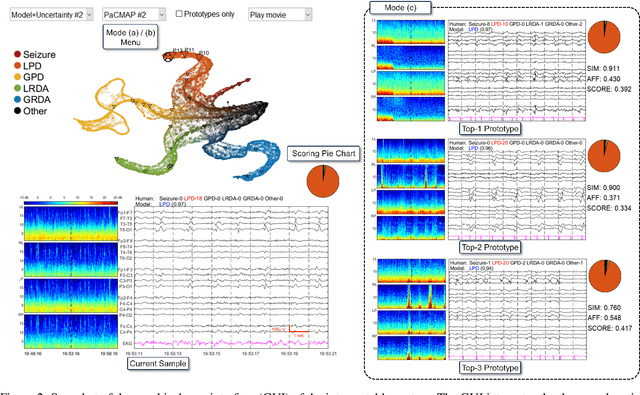
IMPORTANCE: An interpretable machine learning model can provide faithful explanations of each prediction and yet maintain higher performance than its black box counterpart. OBJECTIVE: To design an interpretable machine learning model which accurately predicts EEG protopatterns while providing an explanation of its predictions with assistance of a specialized GUI. To map the cEEG latent features to a 2D space in order to visualize the ictal-interictal-injury continuum and gain insight into its high-dimensional structure. DESIGN, SETTING, AND PARTICIPANTS: 50,697 50-second cEEG samples from 2,711 ICU patients collected between July 2006 and March 2020 at Massachusetts General Hospital. Samples were labeled as one of 6 EEG activities by domain experts, with 124 different experts providing annotations. MAIN OUTCOMES AND MEASURES: Our neural network is interpretable because it uses case-based reasoning: it compares a new EEG reading to a set of learned prototypical EEG samples from the training dataset. Interpretability was measured with task-specific neighborhood agreement statistics. Discriminatory performance was evaluated with AUROC and AUPRC. RESULTS: The model achieves AUROCs of 0.87, 0.93, 0.96, 0.92, 0.93, 0.80 for classes Seizure, LPD, GPD, LRDA, GRDA, Other respectively. This performance is statistically significantly higher than that of the corresponding uninterpretable (black box) model with p<0.0001. Videos of the ictal-interictal-injury continuum are provided. CONCLUSION AND RELEVANCE: Our interpretable model and GUI can act as a reference for practitioners who work with cEEG patterns. We can now better understand the relationships between different types of cEEG patterns. In the future, this system may allow for targeted intervention and training in clinical settings. It could also be used for re-confirming or providing additional information for diagnostics.