 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaestro-U: Leveraging joint speech-text representation learning for zero supervised speech ASR
Paper and Code
Oct 18, 2022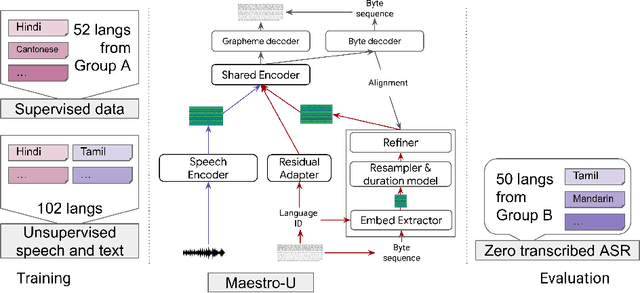
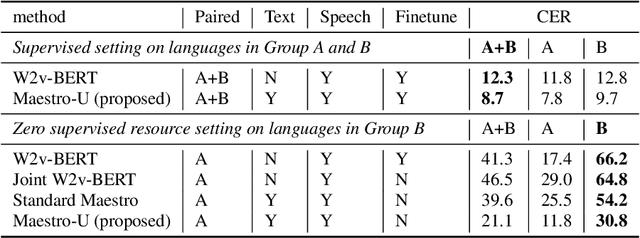
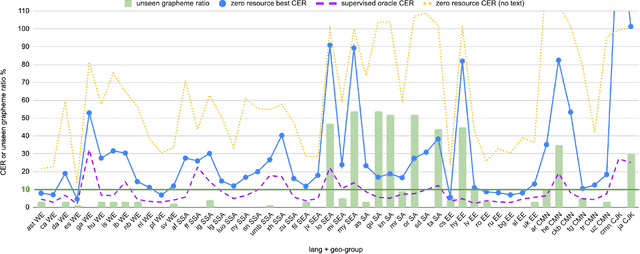
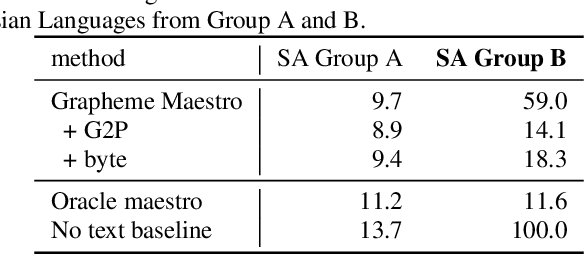
Training state-of-the-art Automated Speech Recognition (ASR) models typically requires a substantial amount of transcribed speech. In this work, we demonstrate that a modality-matched joint speech and text model can be leveraged to train a massively multilingual ASR model without any supervised (manually transcribed) speech for some languages. This paper explores the use of jointly learnt speech and text representations in a massively multilingual, zero supervised speech, real-world setting to expand the set of languages covered by ASR with only unlabeled speech and text in the target languages. Using the FLEURS dataset, we define the task to cover $102$ languages, where transcribed speech is available in $52$ of these languages and can be used to improve end-to-end ASR quality on the remaining $50$. First, we show that by combining speech representations with byte-level text representations and use of language embeddings, we can dramatically reduce the Character Error Rate (CER) on languages with no supervised speech from 64.8\% to 30.8\%, a relative reduction of 53\%. Second, using a subset of South Asian languages we show that Maestro-U can promote knowledge transfer from languages with supervised speech even when there is limited to no graphemic overlap. Overall, Maestro-U closes the gap to oracle performance by 68.5\% relative and reduces the CER of 19 languages below 15\%.