 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRC-Net: Learning Discriminative Features on Point Clouds by Encoding Local Region Contexts
Paper and Code
Mar 21, 2020

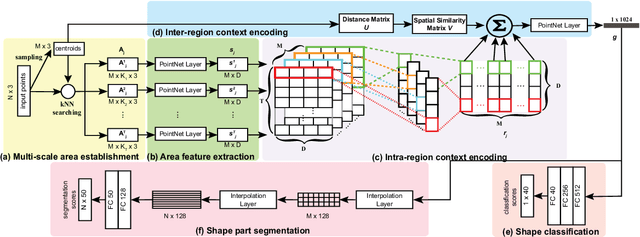

Learning discriminative feature directly on point clouds is still challenging in the understanding of 3D shapes. Recent methods usually partition point clouds into local region sets, and then extract the local region features with fixed-size CNN or MLP, and finally aggregate all individual local features into a global feature using simple max pooling. However, due to the irregularity and sparsity in sampled point clouds, it is hard to encode the fine-grained geometry of local regions and their spatial relationships when only using the fixed-size filters and individual local feature integration, which limit the ability to learn discriminative features. To address this issue, we present a novel Local-Region-Context Network (LRC-Net), to learn discriminative features on point clouds by encoding the fine-grained contexts inside and among local regions simultaneously. LRC-Net consists of two main modules. The first module, named intra-region context encoding, is designed for capturing the geometric correlation inside each local region by novel variable-size convolution filter. The second module, named inter-region context encoding, is proposed for integrating the spatial relationships among local regions based on spatial similarity measures. Experimental results show that LRC-Net is competitive with state-of-the-art methods in shape classification and shape segmentation applications.