 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongAlign: A Recipe for Long Context Alignment of Large Language Models
Paper and Code
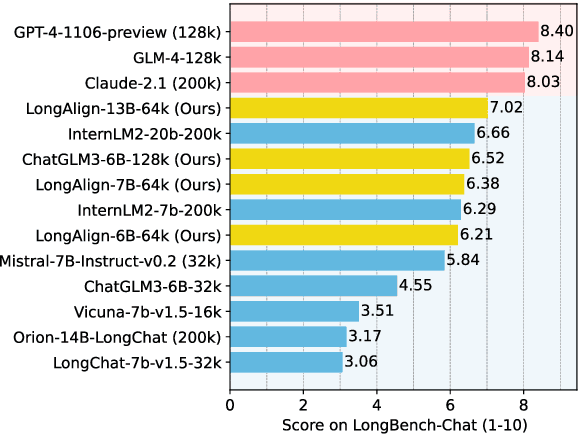


Extending large language models to effectively handle long contexts requires instruction fine-tuning on input sequences of similar length. To address this, we present LongAlign -- a recipe of the instruction data, training, and evaluation for long context alignment. First, we construct a long instruction-following dataset using Self-Instruct. To ensure the data diversity, it covers a broad range of tasks from various long context sources. Second, we adopt the packing and sorted batching strategies to speed up supervised fine-tuning on data with varied length distributions. Additionally, we develop a loss weighting method to balance the contribution to the loss across different sequences during packing training. Third, we introduce the LongBench-Chat benchmark for evaluating instruction-following capabilities on queries of 10k-100k in length. Experiments show that LongAlign outperforms existing recipes for LLMs in long context tasks by up to 30\%, while also maintaining their proficiency in handling short, generic tasks. The code, data, and long-aligned models are open-sourced at https://github.com/THUDM/LongAlign.