 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Private Hypothesis Selection
Paper and Code
Feb 21, 2020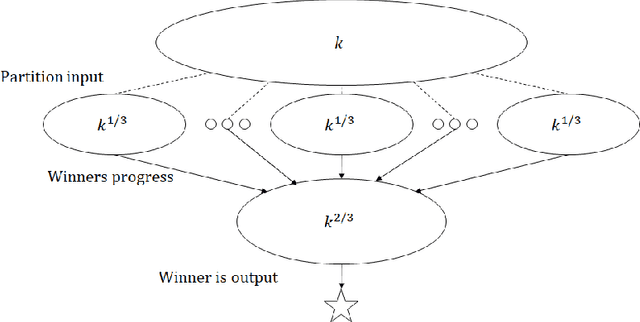
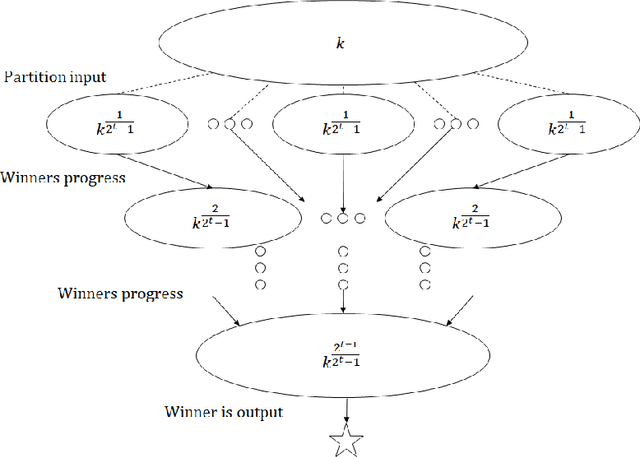
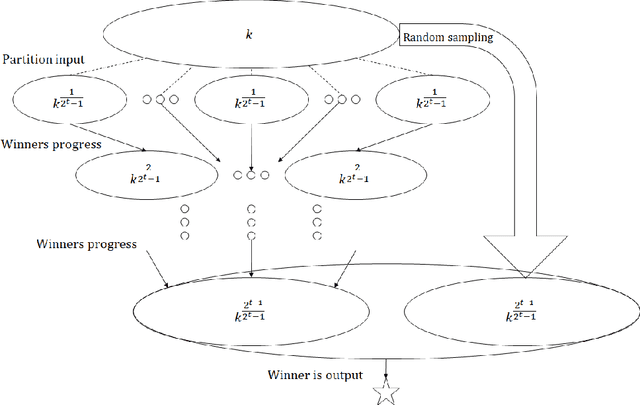
We initiate the study of hypothesis selection under local differential privacy. Given samples from an unknown probability distribution $p$ and a set of $k$ probability distributions $\mathcal{Q}$, we aim to output, under the constraints of $\varepsilon$-local differential privacy, a distribution from $\mathcal{Q}$ whose total variation distance to $p$ is comparable to the best such distribution. This is a generalization of the classic problem of $k$-wise simple hypothesis testing, which corresponds to when $p \in \mathcal{Q}$, and we wish to identify $p$. Absent privacy constraints, this problem requires $O(\log k)$ samples from $p$, and it was recently shown that the same complexity is achievable under (central) differential privacy. However, the naive approach to this problem under local differential privacy would require $\tilde O(k^2)$ samples. We first show that the constraint of local differential privacy incurs an exponential increase in cost: any algorithm for this problem requires at least $\Omega(k)$ samples. Second, for the special case of $k$-wise simple hypothesis testing, we provide a non-interactive algorithm which nearly matches this bound, requiring $\tilde O(k)$ samples. Finally, we provide sequentially interactive algorithms for the general case, requiring $\tilde O(k)$ samples and only $O(\log \log k)$ rounds of interactivity. Our algorithms are achieved through a reduction to maximum selection with adversarial comparators, a problem of independent interest for which we initiate study in the parallel setting. For this problem, we provide a family of algorithms for each number of allowed rounds of interaction $t$, as well as lower bounds showing that they are near-optimal for every $t$. Notably, our algorithms result in exponential improvements on the round complexity of previous methods.