 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Convolutional Neural Network with Gaussian-based Grasping Representation for Robotic Grasping Detection
Paper and Code
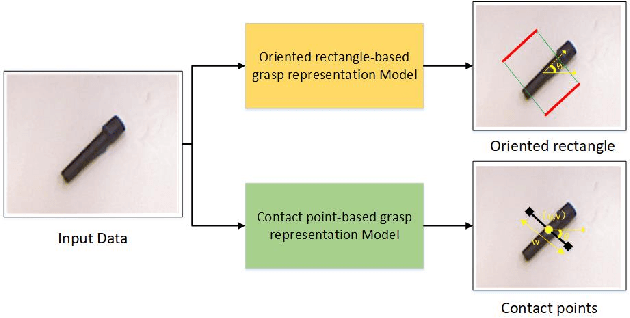
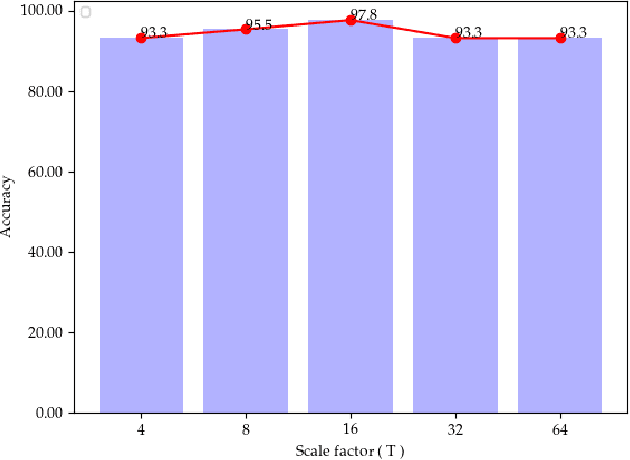


The method of deep learning has achieved excellent results in improving the performance of robotic grasping detection. However, the deep learning methods used in general object detection are not suitable for robotic grasping detection. Current modern object detectors are difficult to strike a balance between high accuracy and fast inference speed. In this paper, we present an efficient and robust fully convolutional neural network model to perform robotic grasping pose estimation from an n-channel input image of the real grasping scene. The proposed network is a lightweight generative architecture for grasping detection in one stage. Specifically, a grasping representation based on Gaussian kernel is introduced to encode training samples, which embodies the principle of maximum central point grasping confidence. Meanwhile, to extract multi-scale information and enhance the feature discriminability, a receptive field block (RFB) is assembled to the bottleneck of our grasping detection architecture. Besides, pixel attention and channel attention are combined to automatically learn to focus on fusing context information of varying shapes and sizes by suppressing the noise feature and highlighting the grasping object feature. Extensive experiments on two public grasping datasets, Cornell and Jacquard demonstrate the state-of-the-art performance of our method in balancing accuracy and inference speed. The network is an order of magnitude smaller than other excellent algorithms while achieving better performance with an accuracy of 98.9$\%$ and 95.6$\%$ on the Cornell and Jacquard datasets, respectively.