 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Unlabeled Whole-Slide-Images for Mitosis Detection
Paper and Code
Jul 31, 2018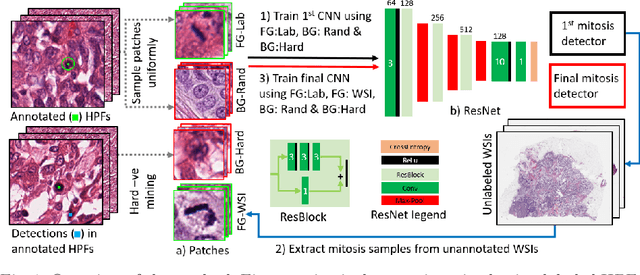
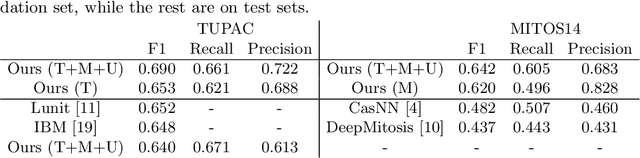
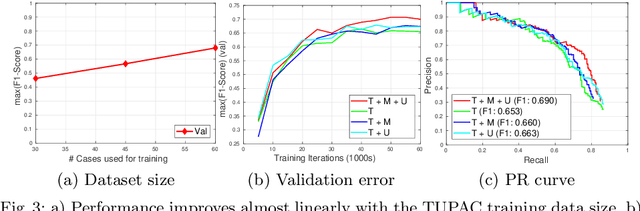
Mitosis count is an important biomarker for prognosis of various cancers. At present, pathologists typically perform manual counting on a few selected regions of interest in breast whole-slide-images (WSIs) of patient biopsies. This task is very time-consuming, tedious and subjective. Automated mitosis detection methods have made great advances in recent years. However, these methods require exhaustive labeling of a large number of selected regions of interest. This task is very expensive because expert pathologists are needed for reliable and accurate annotations. In this paper, we present a semi-supervised mitosis detection method which is designed to leverage a large number of unlabeled breast cancer WSIs. As a result, our method capitalizes on the growing number of digitized histology images, without relying on exhaustive annotations, subsequently improving mitosis detection. Our method first learns a mitosis detector from labeled data, uses this detector to mine additional mitosis samples from unlabeled WSIs, and then trains the final model using this larger and diverse set of mitosis samples. The use of unlabeled data improves F1-score by $\sim$5\% compared to our best performing fully-supervised model on the TUPAC validation set. Our submission (single model) to TUPAC challenge ranks highly on the leaderboard with an F1-score of 0.64.