 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Segment Human by Watching YouTube
Paper and Code
Feb 28, 2018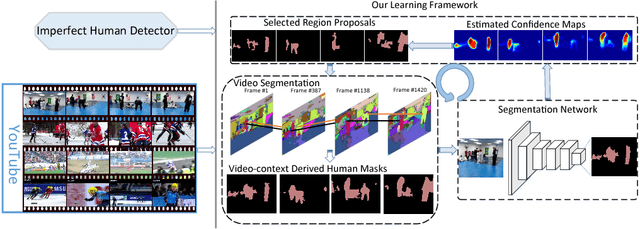
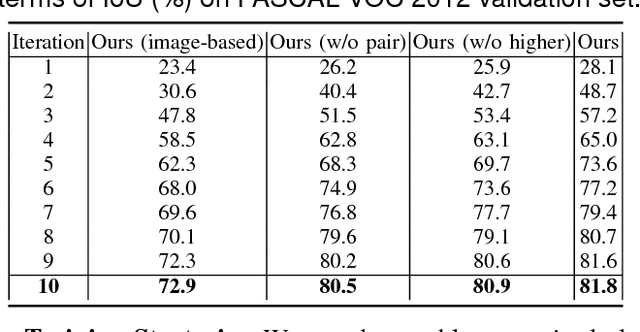
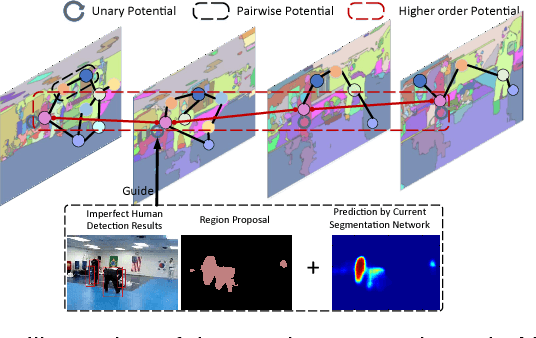
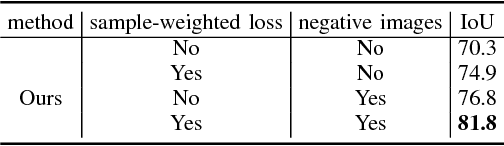
An intuition on human segmentation is that when a human is moving in a video, the video-context (e.g., appearance and motion clues) may potentially infer reasonable mask information for the whole human body. Inspired by this, based on popular deep convolutional neural networks (CNN), we explore a very-weakly supervised learning framework for human segmentation task, where only an imperfect human detector is available along with massive weakly-labeled YouTube videos. In our solution, the video-context guided human mask inference and CNN based segmentation network learning iterate to mutually enhance each other until no further improvement gains. In the first step, each video is decomposed into supervoxels by the unsupervised video segmentation. The superpixels within the supervoxels are then classified as human or non-human by graph optimization with unary energies from the imperfect human detection results and the predicted confidence maps by the CNN trained in the previous iteration. In the second step, the video-context derived human masks are used as direct labels to train CNN. Extensive experiments on the challenging PASCAL VOC 2012 semantic segmentation benchmark demonstrate that the proposed framework has already achieved superior results than all previous weakly-supervised methods with object class or bounding box annotations. In addition, by augmenting with the annotated masks from PASCAL VOC 2012, our method reaches a new state-of-the-art performance on the human segmentation task.