 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Weakly-labeled Web Videos via Exploring Sub-Concepts
Paper and Code
Jan 11, 2021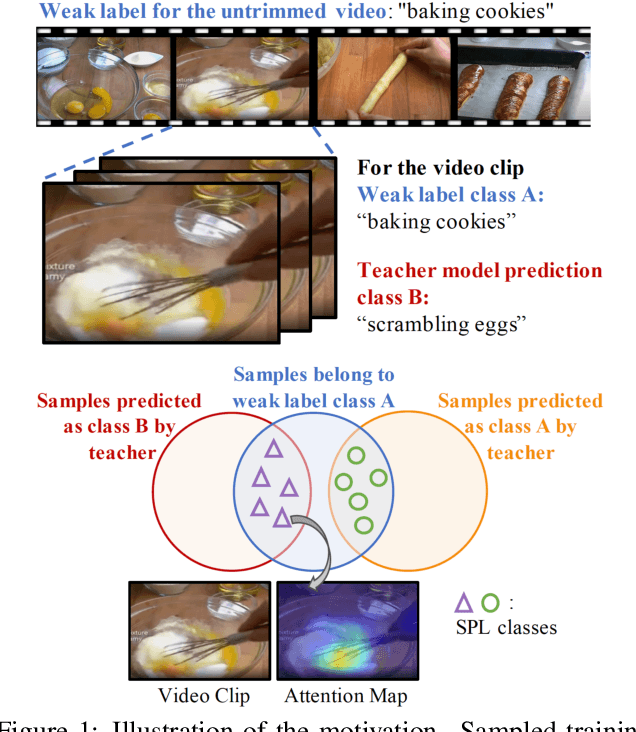
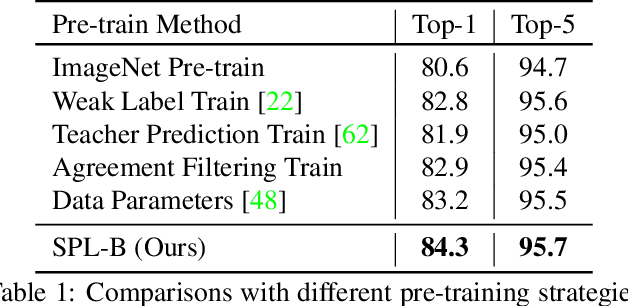

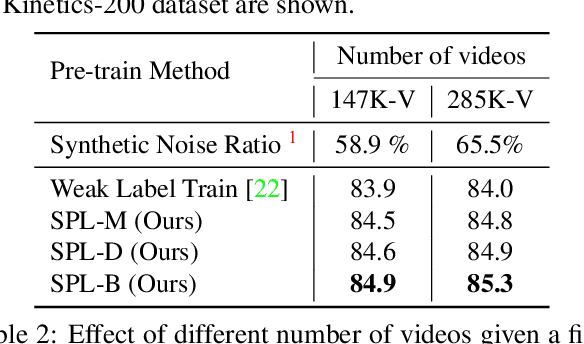
Learning visual knowledge from massive weakly-labeled web videos has attracted growing research interests thanks to the large corpus of easily accessible video data on the Internet. However, for video action recognition, the action of interest might only exist in arbitrary clips of untrimmed web videos, resulting in high label noises in the temporal space. To address this issue, we introduce a new method for pre-training video action recognition models using queried web videos. Instead of trying to filter out, we propose to convert the potential noises in these queried videos to useful supervision signals by defining the concept of Sub-Pseudo Label (SPL). Specifically, SPL spans out a new set of meaningful "middle ground" label space constructed by extrapolating the original weak labels during video querying and the prior knowledge distilled from a teacher model. Consequently, SPL provides enriched supervision for video models to learn better representations. SPL is fairly simple and orthogonal to popular teacher-student self-training frameworks without extra training cost. We validate the effectiveness of our method on four video action recognition datasets and a weakly-labeled image dataset to study the generalization ability. Experiments show that SPL outperforms several existing pre-training strategies using pseudo-labels and the learned representations lead to competitive results when fine-tuning on HMDB-51 and UCF-101 compared with recent pre-training methods.