 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Contrastive Representation for Semantic Correspondence
Paper and Code
Sep 22, 2021
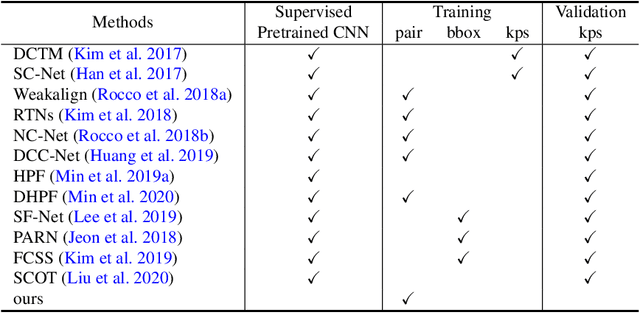
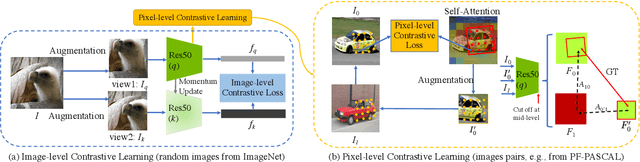
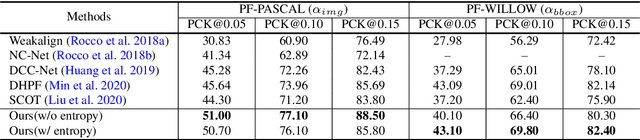
Dense correspondence across semantically related images has been extensively studied, but still faces two challenges: 1) large variations in appearance, scale and pose exist even for objects from the same category, and 2) labeling pixel-level dense correspondences is labor intensive and infeasible to scale. Most existing approaches focus on designing various matching approaches with fully-supervised ImageNet pretrained networks. On the other hand, while a variety of self-supervised approaches are proposed to explicitly measure image-level similarities, correspondence matching the pixel level remains under-explored. In this work, we propose a multi-level contrastive learning approach for semantic matching, which does not rely on any ImageNet pretrained model. We show that image-level contrastive learning is a key component to encourage the convolutional features to find correspondence between similar objects, while the performance can be further enhanced by regularizing cross-instance cycle-consistency at intermediate feature levels. Experimental results on the PF-PASCAL, PF-WILLOW, and SPair-71k benchmark datasets demonstrate that our method performs favorably against the state-of-the-art approaches. The source code and trained models will be made available to the public.