 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer Based Fine-grained Visual Classification
Paper and Code
Dec 21, 2020
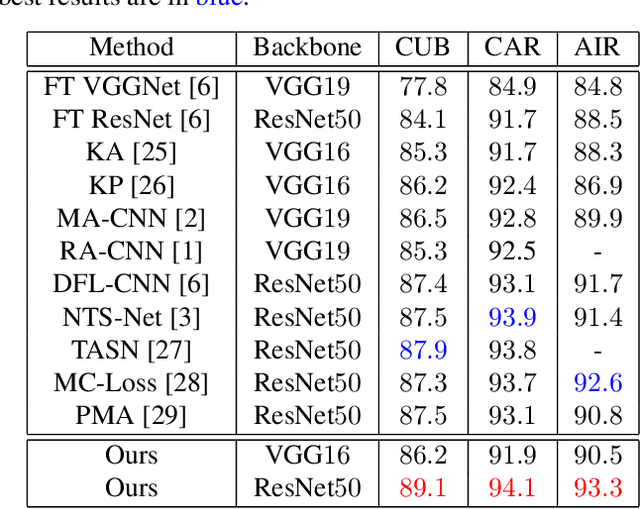
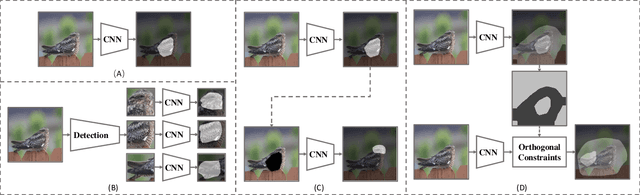

Fine-grained visual classification (FGVC) aims to distinguish the sub-classes of the same category and its essential solution is to mine the subtle and discriminative regions. Convolution neural networks (CNNs), which employ the cross entropy loss (CE-loss) as the loss function, show poor performance since the model can only learn the most discriminative part and ignore other meaningful regions. Some existing works try to solve this problem by mining more discriminative regions by some detection techniques or attention mechanisms. However, most of them will meet the background noise problem when trying to find more discriminative regions. In this paper, we address it in a knowledge transfer learning manner. Multiple models are trained one by one, and all previously trained models are regarded as teacher models to supervise the training of the current one. Specifically, a orthogonal loss (OR-loss) is proposed to encourage the network to find diverse and meaningful regions. In addition, the first model is trained with only CE-Loss. Finally, all models' outputs with complementary knowledge are combined together for the final prediction result. We demonstrate the superiority of the proposed method and obtain state-of-the-art (SOTA) performances on three popular FGVC datasets.