Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Audio and Speech Understanding
Paper and Code
Oct 02, 2023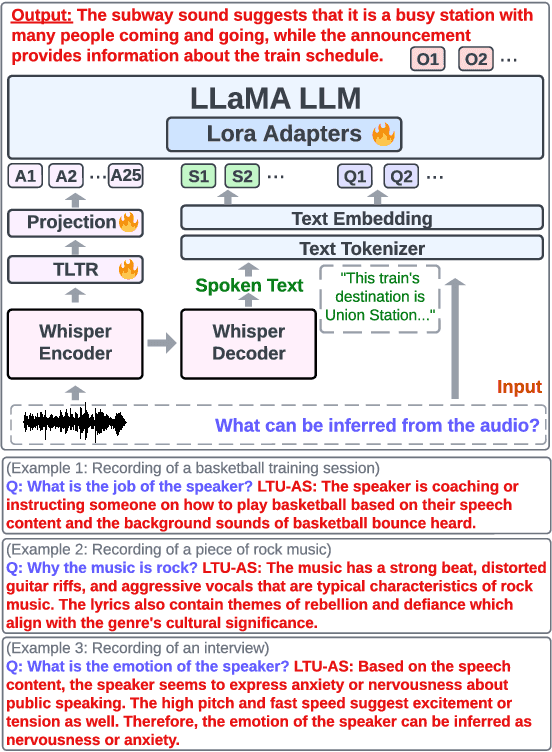



Humans are surrounded by audio signals that include both speech and non-speech sounds. The recognition and understanding of speech and non-speech audio events, along with a profound comprehension of the relationship between them, constitute fundamental cognitive capabilities. For the first time, we build a machine learning model, called LTU-AS, that has a conceptually similar universal audio perception and advanced reasoning ability. Specifically, by integrating Whisper as a perception module and LLaMA as a reasoning module, LTU-AS can simultaneously recognize and jointly understand spoken text, speech paralinguistics, and non-speech audio events - almost everything perceivable from audio signals.
* Accepted at ASRU 2023. Interactive demo at
https://huggingface.co/spaces/yuangongfdu/ltu-2
View paper on