Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Dense Retrieval as Mixture of Topics
Paper and Code
Nov 27, 2021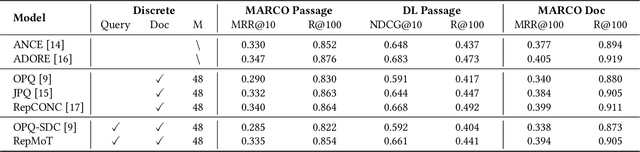
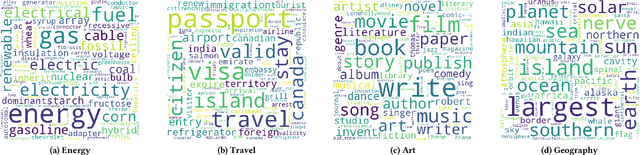

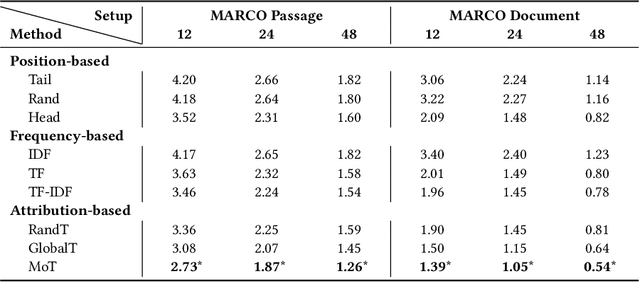
Dense Retrieval (DR) reaches state-of-the-art results in first-stage retrieval, but little is known about the mechanisms that contribute to its success. Therefore, in this work, we conduct an interpretation study of recently proposed DR models. Specifically, we first discretize the embeddings output by the document and query encoders. Based on the discrete representations, we analyze the attribution of input tokens. Both qualitative and quantitative experiments are carried out on public test collections. Results suggest that DR models pay attention to different aspects of input and extract various high-level topic representations. Therefore, we can regard the representations learned by DR models as a mixture of high-level topics.
View paper on