 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferGrad: Improving Diffusion Models for Vocoder by Considering Inference in Training
Paper and Code


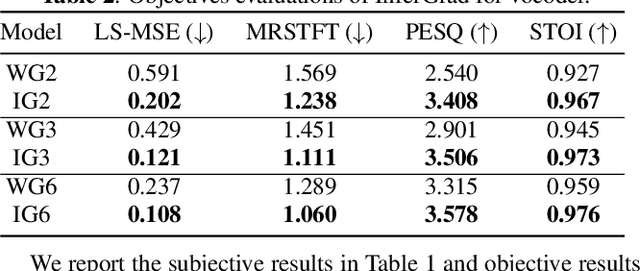

Denoising diffusion probabilistic models (diffusion models for short) require a large number of iterations in inference to achieve the generation quality that matches or surpasses the state-of-the-art generative models, which invariably results in slow inference speed. Previous approaches aim to optimize the choice of inference schedule over a few iterations to speed up inference. However, this results in reduced generation quality, mainly because the inference process is optimized separately, without jointly optimizing with the training process. In this paper, we propose InferGrad, a diffusion model for vocoder that incorporates inference process into training, to reduce the inference iterations while maintaining high generation quality. More specifically, during training, we generate data from random noise through a reverse process under inference schedules with a few iterations, and impose a loss to minimize the gap between the generated and ground-truth data samples. Then, unlike existing approaches, the training of InferGrad considers the inference process. The advantages of InferGrad are demonstrated through experiments on the LJSpeech dataset showing that InferGrad achieves better voice quality than the baseline WaveGrad under same conditions while maintaining the same voice quality as the baseline but with $3$x speedup ($2$ iterations for InferGrad vs $6$ iterations for WaveGrad).