 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Machine Speech Chain Towards Enabling Listening while Speaking in Real-time
Paper and Code
Nov 04, 2020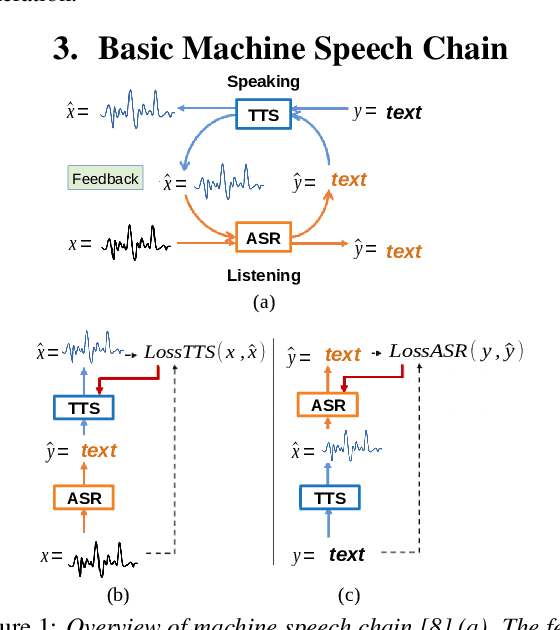
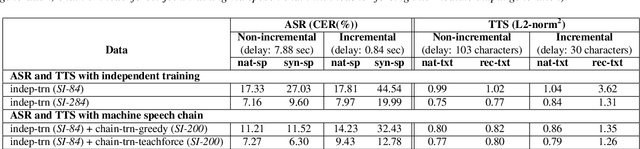
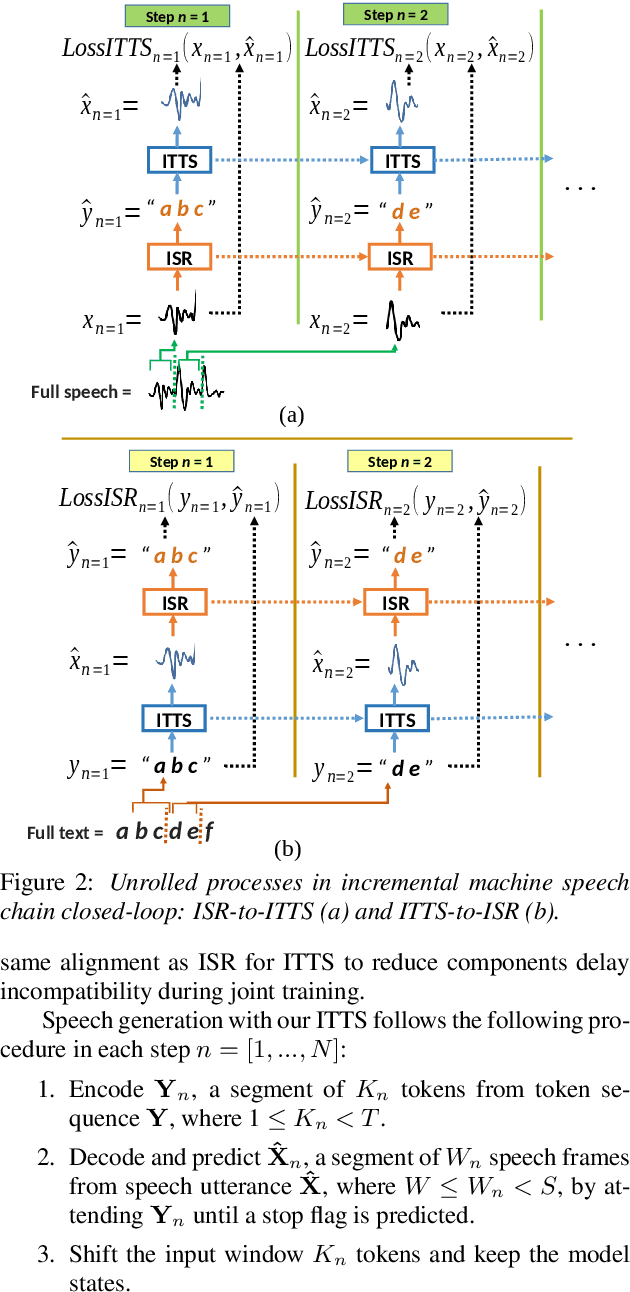
Inspired by a human speech chain mechanism, a machine speech chain framework based on deep learning was recently proposed for the semi-supervised development of automatic speech recognition (ASR) and text-to-speech synthesis TTS) systems. However, the mechanism to listen while speaking can be done only after receiving entire input sequences. Thus, there is a significant delay when encountering long utterances. By contrast, humans can listen to what hey speak in real-time, and if there is a delay in hearing, they won't be able to continue speaking. In this work, we propose an incremental machine speech chain towards enabling machine to listen while speaking in real-time. Specifically, we construct incremental ASR (ISR) and incremental TTS (ITTS) by letting both systems improve together through a short-term loop. Our experimental results reveal that our proposed framework is able to reduce delays due to long utterances while keeping a comparable performance to the non-incremental basic machine speech chain.