 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagining Grounded Conceptual Representations from Perceptual Information in Situated Guessing Games
Paper and Code

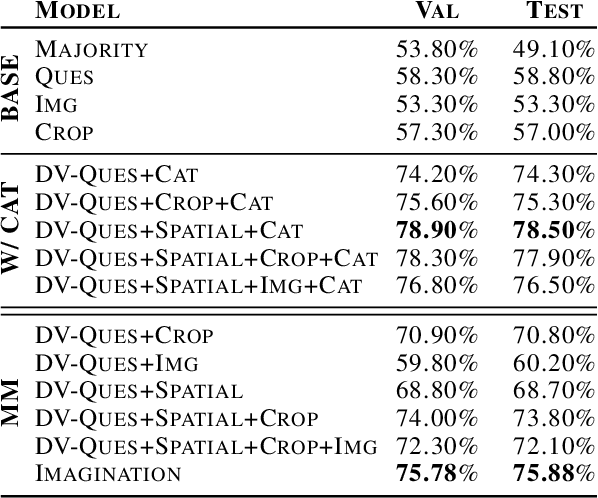


In visual guessing games, a Guesser has to identify a target object in a scene by asking questions to an Oracle. An effective strategy for the players is to learn conceptual representations of objects that are both discriminative and expressive enough to ask questions and guess correctly. However, as shown by Suglia et al. (2020), existing models fail to learn truly multi-modal representations, relying instead on gold category labels for objects in the scene both at training and inference time. This provides an unnatural performance advantage when categories at inference time match those at training time, and it causes models to fail in more realistic "zero-shot" scenarios where out-of-domain object categories are involved. To overcome this issue, we introduce a novel "imagination" module based on Regularized Auto-Encoders, that learns context-aware and category-aware latent embeddings without relying on category labels at inference time. Our imagination module outperforms state-of-the-art competitors by 8.26% gameplay accuracy in the CompGuessWhat?! zero-shot scenario (Suglia et al., 2020), and it improves the Oracle and Guesser accuracy by 2.08% and 12.86% in the GuessWhat?! benchmark, when no gold categories are available at inference time. The imagination module also boosts reasoning about object properties and attributes.