 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI2CR: Improving Noise Robustness on Keyword Spotting Using Inter-Intra Contrastive Regularization
Paper and Code
Sep 14, 2022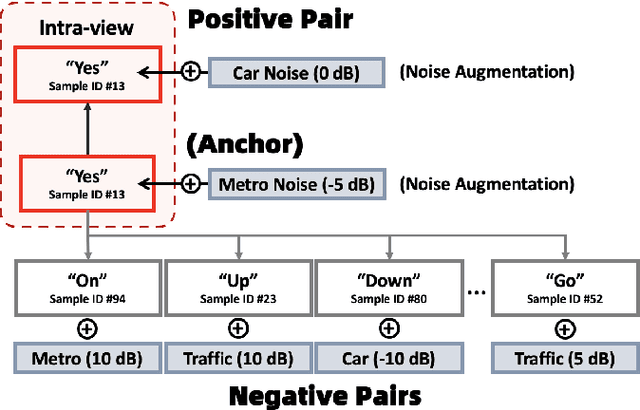
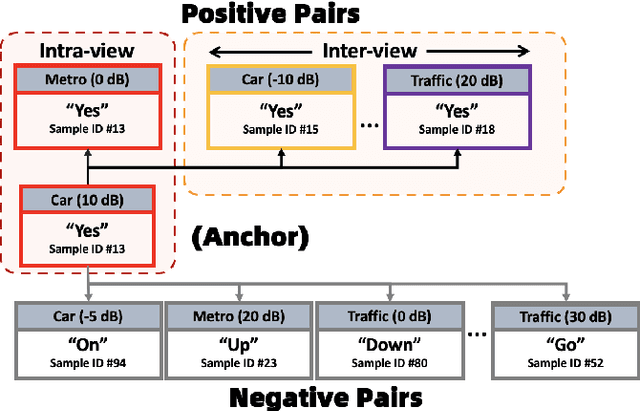
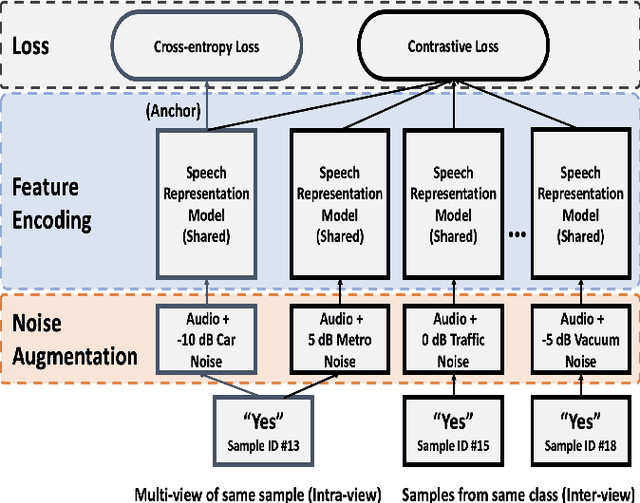

Noise robustness in keyword spotting remains a challenge as many models fail to overcome the heavy influence of noises, causing the deterioration of the quality of feature embeddings. We proposed a contrastive regularization method called Inter-Intra Contrastive Regularization (I2CR) to improve the feature representations by guiding the model to learn the fundamental speech information specific to the cluster. This involves maximizing the similarity across Intra and Inter samples of the same class. As a result, it pulls the instances closer to more generalized representations that form more prominent clusters and reduces the adverse impact of noises. We show that our method provides consistent improvements in accuracy over different backbone model architectures under different noise environments. We also demonstrate that our proposed framework has improved the accuracy of unseen out-of-domain noises and unseen variant noise SNRs. This indicates the significance of our work with the overall refinement in noise robustness.