 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspherical Variational Auto-Encoders
Paper and Code
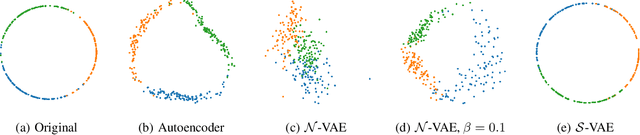
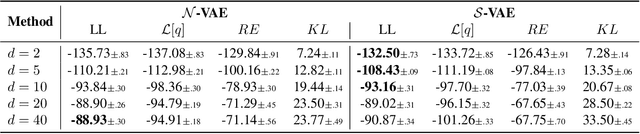

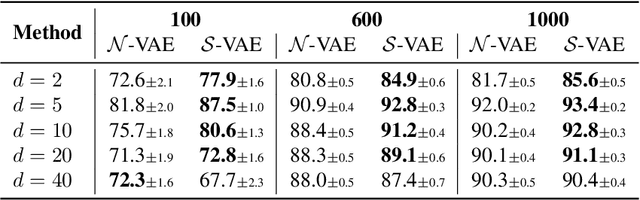
The Variational Auto-Encoder (VAE) is one of the most used unsupervised machine learning models. But although the default choice of a Gaussian distribution for both the prior and posterior represents a mathematically convenient distribution often leading to competitive results, we show that this parameterization fails to model data with a latent hyperspherical structure. To address this issue we propose using a von Mises-Fisher (vMF) distribution instead, leading to a hyperspherical latent space. Through a series of experiments we show how such a hyperspherical VAE, or $\mathcal{S}$-VAE, is more suitable for capturing data with a hyperspherical latent structure, while outperforming a normal, $\mathcal{N}$-VAE, in low dimensions on other data types.