 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Shared Control via Frequency-based Policy Dissection
Paper and Code
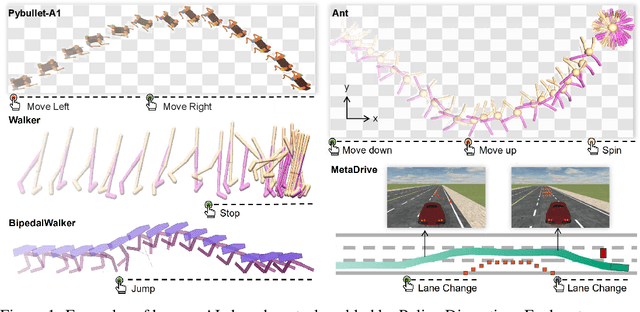
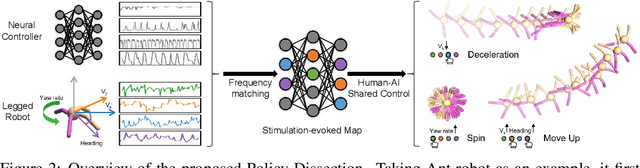


Human-AI shared control allows human to interact and collaborate with AI to accomplish control tasks in complex environments. Previous Reinforcement Learning (RL) methods attempt the goal-conditioned design to achieve human-controllable policies at the cost of redesigning the reward function and training paradigm. Inspired by the neuroscience approach to investigate the motor cortex in primates, we develop a simple yet effective frequency-based approach called \textit{Policy Dissection} to align the intermediate representation of the learned neural controller with the kinematic attributes of the agent behavior. Without modifying the neural controller or retraining the model, the proposed approach can convert a given RL-trained policy into a human-interactive policy. We evaluate the proposed approach on the RL tasks of autonomous driving and locomotion. The experiments show that human-AI shared control achieved by Policy Dissection in driving task can substantially improve the performance and safety in unseen traffic scenes. With human in the loop, the locomotion robots also exhibit versatile controllable motion skills even though they are only trained to move forward. Our results suggest the promising direction of implementing human-AI shared autonomy through interpreting the learned representation of the autonomous agents. Demo video and code will be made available at https://metadriverse.github.io/policydissect.