 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Attention Network for Action Recognition in Videos
Paper and Code
Jul 21, 2016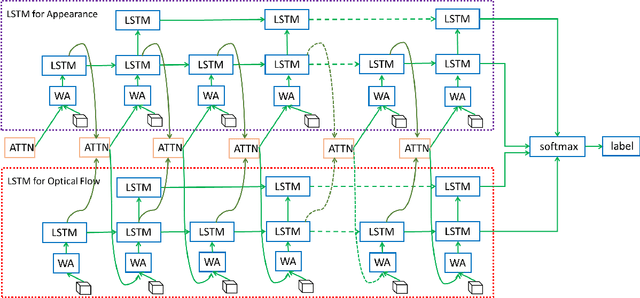


Understanding human actions in wild videos is an important task with a broad range of applications. In this paper we propose a novel approach named Hierarchical Attention Network (HAN), which enables to incorporate static spatial information, short-term motion information and long-term video temporal structures for complex human action understanding. Compared to recent convolutional neural network based approaches, HAN has following advantages (1) HAN can efficiently capture video temporal structures in a longer range; (2) HAN is able to reveal temporal transitions between frame chunks with different time steps, i.e. it explicitly models the temporal transitions between frames as well as video segments and (3) with a multiple step spatial temporal attention mechanism, HAN automatically learns important regions in video frames and temporal segments in the video. The proposed model is trained and evaluated on the standard video action benchmarks, i.e., UCF-101 and HMDB-51, and it significantly outperforms the state-of-the arts