 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHET: Scaling out Huge Embedding Model Training via Cache-enabled Distributed Framework
Paper and Code
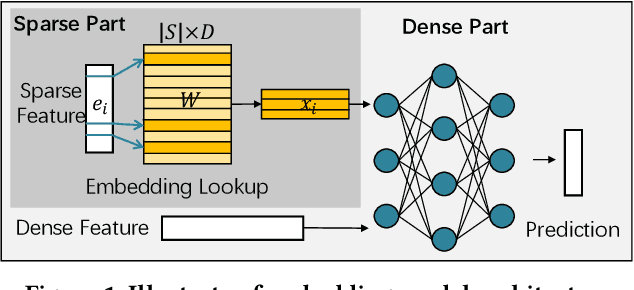
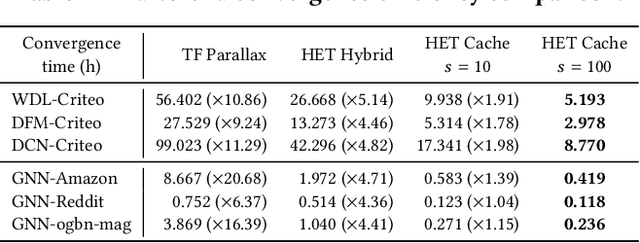
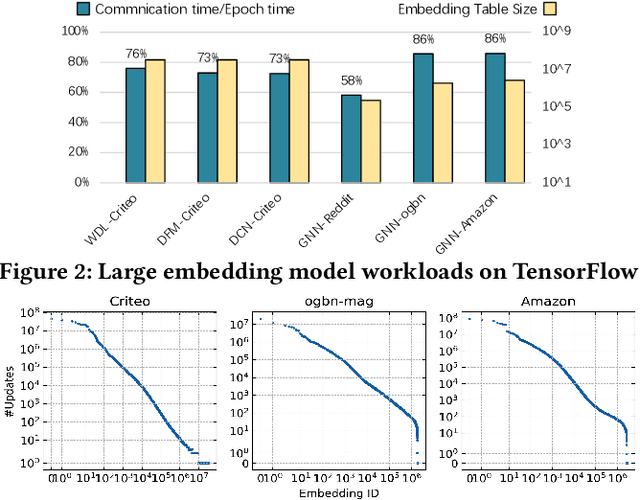
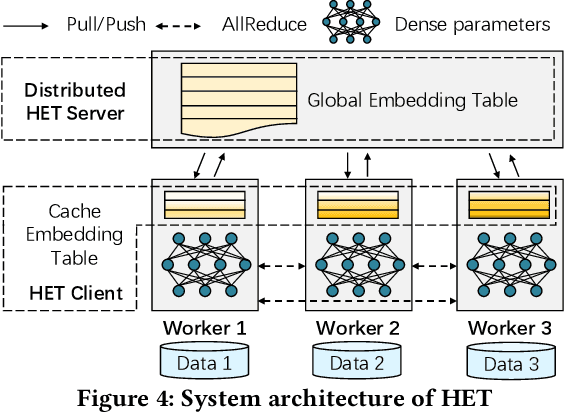
Embedding models have been an effective learning paradigm for high-dimensional data. However, one open issue of embedding models is that their representations (latent factors) often result in large parameter space. We observe that existing distributed training frameworks face a scalability issue of embedding models since updating and retrieving the shared embedding parameters from servers usually dominates the training cycle. In this paper, we propose HET, a new system framework that significantly improves the scalability of huge embedding model training. We embrace skewed popularity distributions of embeddings as a performance opportunity and leverage it to address the communication bottleneck with an embedding cache. To ensure consistency across the caches, we incorporate a new consistency model into HET design, which provides fine-grained consistency guarantees on a per-embedding basis. Compared to previous work that only allows staleness for read operations, HET also utilizes staleness for write operations. Evaluations on six representative tasks show that HET achieves up to 88% embedding communication reductions and up to 20.68x performance speedup over the state-of-the-art baselines.