 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding 3D Scene Affordance From Egocentric Interactions
Paper and Code
Sep 29, 2024
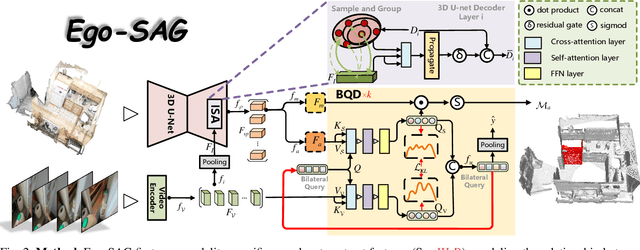
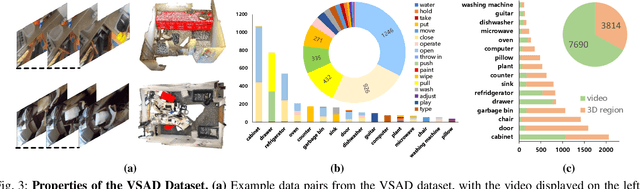

Grounding 3D scene affordance aims to locate interactive regions in 3D environments, which is crucial for embodied agents to interact intelligently with their surroundings. Most existing approaches achieve this by mapping semantics to 3D instances based on static geometric structure and visual appearance. This passive strategy limits the agent's ability to actively perceive and engage with the environment, making it reliant on predefined semantic instructions. In contrast, humans develop complex interaction skills by observing and imitating how others interact with their surroundings. To empower the model with such abilities, we introduce a novel task: grounding 3D scene affordance from egocentric interactions, where the goal is to identify the corresponding affordance regions in a 3D scene based on an egocentric video of an interaction. This task faces the challenges of spatial complexity and alignment complexity across multiple sources. To address these challenges, we propose the Egocentric Interaction-driven 3D Scene Affordance Grounding (Ego-SAG) framework, which utilizes interaction intent to guide the model in focusing on interaction-relevant sub-regions and aligns affordance features from different sources through a bidirectional query decoder mechanism. Furthermore, we introduce the Egocentric Video-3D Scene Affordance Dataset (VSAD), covering a wide range of common interaction types and diverse 3D environments to support this task. Extensive experiments on VSAD validate both the feasibility of the proposed task and the effectiveness of our approach.